VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



03 trụ cột Log, Metrics, và Traces (Nhật ký, số liệu và dấu vết) của observability
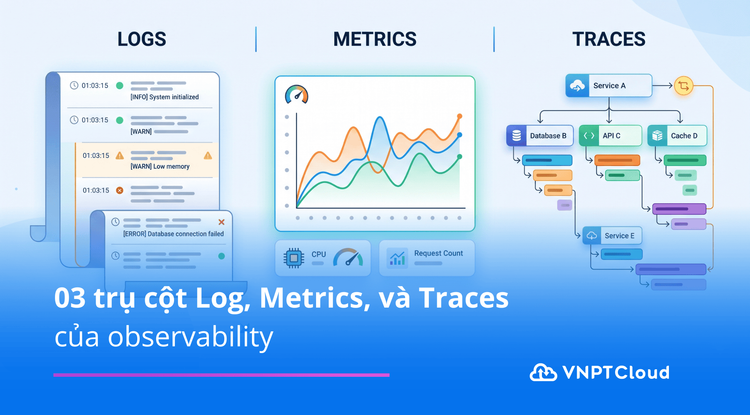

Trong kiến trúc hệ thống hiện đại, Observability (tính quan sát) không chỉ đơn thuần là theo dõi (monitoring). Nó là khả năng thấu hiểu trạng thái bên trong của hệ thống dựa trên những dữ liệu đầu ra. Để đạt được điều này, chúng ta cần dựa vào "kiềng ba chân" vững chắc: Logs, Metrics và Traces.
Log (Nhật ký) - Bản ghi sự kiện chi tiết
Log là tập hợp các bản ghi bất biến, ghi lại những sự kiện cụ thể xảy ra trong hệ thống tại một thời điểm nhất định. Đây là nguồn dữ liệu lâu đời và phổ biến nhất.
- Bản chất kỹ thuật: Mỗi dòng log thường chứa Timestamp (thời điểm xảy ra), Level (mức độ nghiêm trọng như INFO, WARN, ERROR) và Payload (nội dung chi tiết của sự kiện).
- Phân loại:
- Plaintext Logs: Dễ đọc cho con người nhưng khó cho máy móc xử lý trên diện rộng.
- Structured Logs (JSON): Định dạng chuẩn giúp các công cụ phân tích (như ELK Stack) dễ dàng lọc, tìm kiếm và phân tách dữ liệu nhanh chóng.
- Giá trị cốt lõi: Log cung cấp ngữ cảnh cực kỳ chi tiết. Khi bạn đã khoanh vùng được dịch vụ lỗi, log là thứ duy nhất cho bạn biết chính xác biến số nào bị sai hoặc dòng code nào gây ra ngoại lệ (exception).
Metrics (Số liệu) - Bức tranh sức khỏe tổng thể
Khác với Log, Metrics là dữ liệu dạng số được tổng hợp theo thời gian. Nó không tập trung vào từng sự kiện riêng lẻ mà tập trung vào xu hướng và trạng thái của hệ thống.
- Bản chất kỹ thuật: Metrics thường được lưu trữ dưới dạng Time-series data (chuỗi thời gian). Một metric tiêu chuẩn bao gồm: Tên metric, các nhãn (Labels/Tags) để phân loại và giá trị số.
- Các loại Metric phổ biến:
- Gauge: Giá trị có thể tăng hoặc giảm (ví dụ: dung lượng RAM hiện tại, nhiệt độ CPU).
- Counter: Giá trị chỉ có tăng (ví dụ: tổng số lượng yêu cầu đã nhận, tổng số lỗi).
- Histogram/Summary: Dùng để đo lường phân phối (ví dụ: 95% yêu cầu có thời gian phản hồi dưới 200ms).
- Giá trị cốt lõi: Metrics cực kỳ tiết kiệm tài nguyên lưu trữ và có tốc độ truy vấn rất nhanh. Đây là công cụ hàng đầu để thiết lập dashboard giám sát và hệ thống cảnh báo (alerting) tự động khi có bất thường xảy ra.
Traces (Dấu vết) - Hành trình xuyên suốt hệ thống
Traces (hay Distributed Tracing) ghi lại toàn bộ vòng đời của một request khi nó di chuyển qua các thành phần của hệ thống phân tán hoặc Microservices.
- Bản chất kỹ thuật:
- Trace ID: Một định danh duy nhất cho toàn bộ hành trình của một request từ đầu đến cuối.
- Span: Đại diện cho một đơn vị công việc trong một dịch vụ đơn lẻ. Mỗi Span có ID riêng, thời gian bắt đầu/kết thúc và tham chiếu đến Parent Span (Span cha) để tạo thành cấu trúc cây.
- Context Propagation: Kỹ thuật truyền Trace ID qua các tiêu đề (headers) khi gọi API giữa các dịch vụ.
- Giá trị cốt lõi: Traces giải quyết bài toán "Sự phụ thuộc". Nó cho bạn thấy rõ một request bị chậm là do dịch vụ A, dịch vụ B hay do một truy vấn database ở tận cùng hệ thống. Nếu không có Traces, việc tìm điểm nghẽn trong hệ thống có hàng trăm microservices là điều gần như không thể.
Cách Log, Metrics, và Traces phối hợp trong Observability
Ba trụ cột này không hoạt động độc lập mà bổ trợ lẫn nhau để tạo nên một quy trình xử lý sự cố hoàn chỉnh:
- Metrics - Phát hiện (Detection): Số liệu cho bạn biết Cái gì đang xảy ra (Ví dụ: Tỷ lệ lỗi 5xx tăng đột biến trên trang thanh toán).
- Traces - Định vị (Isolation): Sau khi phát hiện lỗi qua Metrics, bạn dùng Traces để xem yêu cầu đó bị hỏng ở dịch vụ nào trong hệ thống phân tán. Nó giúp bạn thu hẹp phạm vi từ hàng trăm dịch vụ xuống một điểm duy nhất.
- Logs - Phân tích (Identification): Cuối cùng, bạn kiểm tra Logs của dịch vụ đã được khoanh vùng để biết Tại sao nó lỗi (Ví dụ: Một dòng thông báo lỗi "NullPointerException" trong log sẽ chỉ ra đúng đoạn mã gây hỏng).
Kết luận: Một hệ thống có tính quan sát tốt cần sự kết hợp hài hòa của cả ba. Thiếu Metrics, bạn không biết khi nào cần hành động; thiếu Traces, bạn mất phương hướng trong hệ thống phức tạp; và thiếu Logs, bạn không thể tìm ra nguyên nhân gốc rễ để sửa lỗi triệt để.