VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



Bottleneck là gì? Hiểu rõ về điểm nghẽn trong hạ tầng công nghệ


Không phải toàn bộ hệ thống sụp đổ cùng lúc, chỉ một thành phần duy nhất chạm ngưỡng giới hạn là đủ để triệt tiêu hiệu năng của toàn bộ hạ tầng phía trên. Cùng VNPT Cloud phân tích Bottleneck là gì, cơ chế hình thành và cách nhận diện sớm để chủ động tối ưu hiệu suất hệ thống trước khi sự cố xảy ra.
Bottleneck là gì?
Bottleneck (Nút thắt cổ chai) là thuật ngữ dùng để chỉ một vị trí hoặc một thành phần cụ thể trên hệ thống/quy trình mà tại đó tốc độ dòng chảy bị kéo chậm lại do giới hạn về năng lực hoặc không gian tài nguyên.
Trong công nghệ và máy tính, Bottleneck (Điểm nghẽn hạ tầng) là tình trạng xảy ra khi các máy chủ, mạng lưới hoặc kho lưu trữ không có đủ dung lượng để đáp ứng khối lượng truy cập hiện tại, trực tiếp cản trở hệ thống vận hành ở mức công suất tối đa. Điểm nghẽn này thường khu trú tại các tài nguyên phần cứng hoặc cấu trúc phần mềm bị tranh chấp quá mức như tốc độ xử lý của CPU, dung lượng bộ nhớ (RAM), giới hạn băng thông mạng, hoặc hiệu suất đọc/ghi dữ liệu ổ cứng (I/O).
Bottleneck làm suy giảm nghiêm trọng hiệu suất ứng dụng (đặc biệt là các nền tảng cơ sở dữ liệu lớn), gây trì trệ dịch vụ và có thể làm sập hệ thống nếu tình trạng quá tải nghiêm trọng diễn ra liên tục.
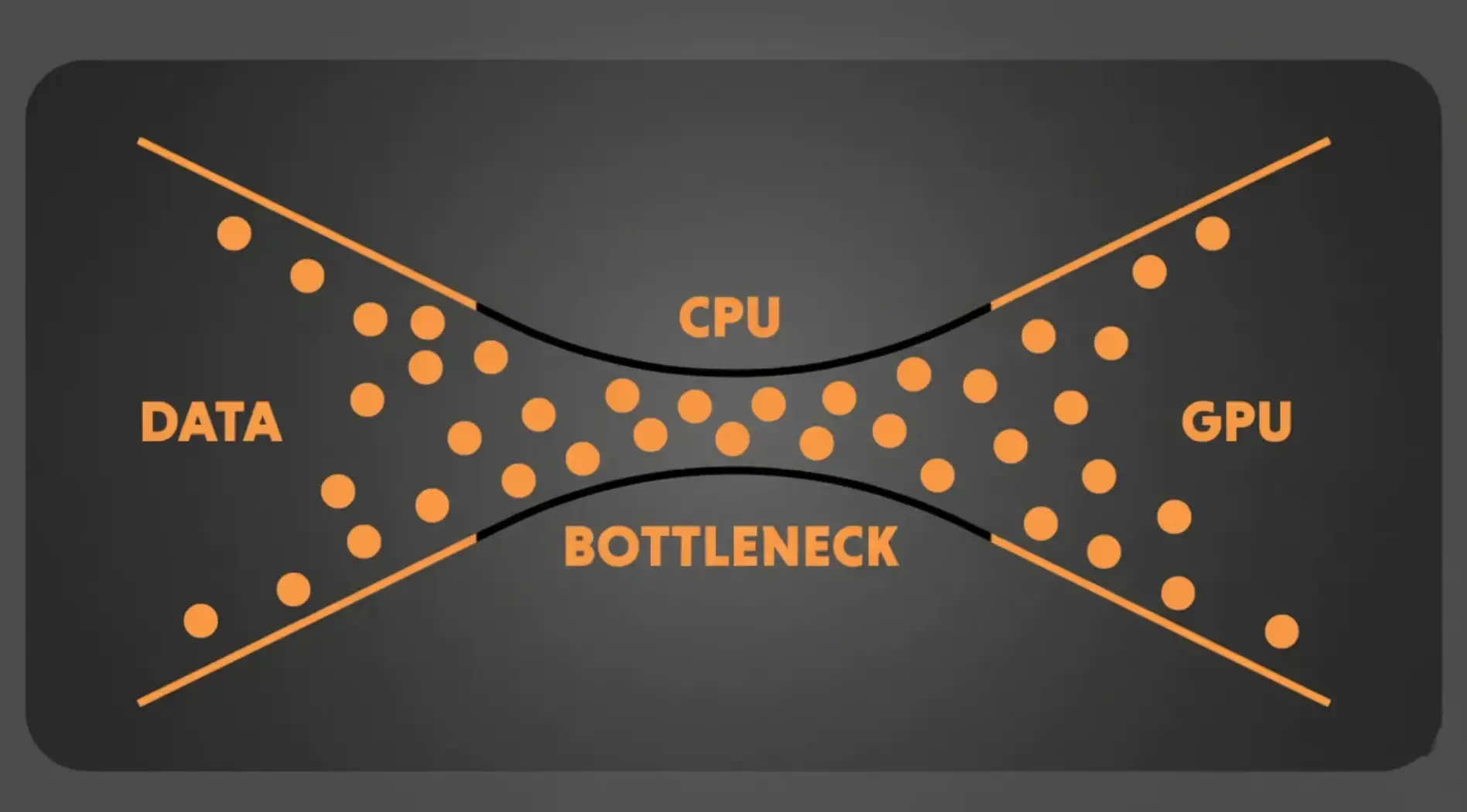
Ví dụ về Bottleneck
Xét ví dụ thực tế về nút thắt cổ chai ở ở tầng lưu trữ trong một hệ thống thương mại điện tử vào đợt Flash Sale lúc 0h00:
Khi hệ thống tự động scale từ 5 lên 30 máy chủ ảo để xử lý lưu lượng tăng đột biến, hàng chục nghìn lệnh bị đẩy xuống một database server duy nhất, trong khi ổ SSD trên máy chủ bị nhà cung cấp đám mây giới hạn cứng ở mức 3.000 IOPS.
Khi Disk I/O chạm ngưỡng 3.000 IOPS, ổ cứng không thể tiếp nhận thêm lệnh ghi. Các truy vấn bắt đầu xếp hàng chờ, thời gian phản hồi leo từ 50 mili-giây lên 12 giây. Người dùng bấm "Thanh toán" nhưng hệ thống trả về lỗi liên tục, doanh thu sụt giảm theo từng phút, trong khi CPU vẫn còn hơn 50% công suất chưa được dùng đến.
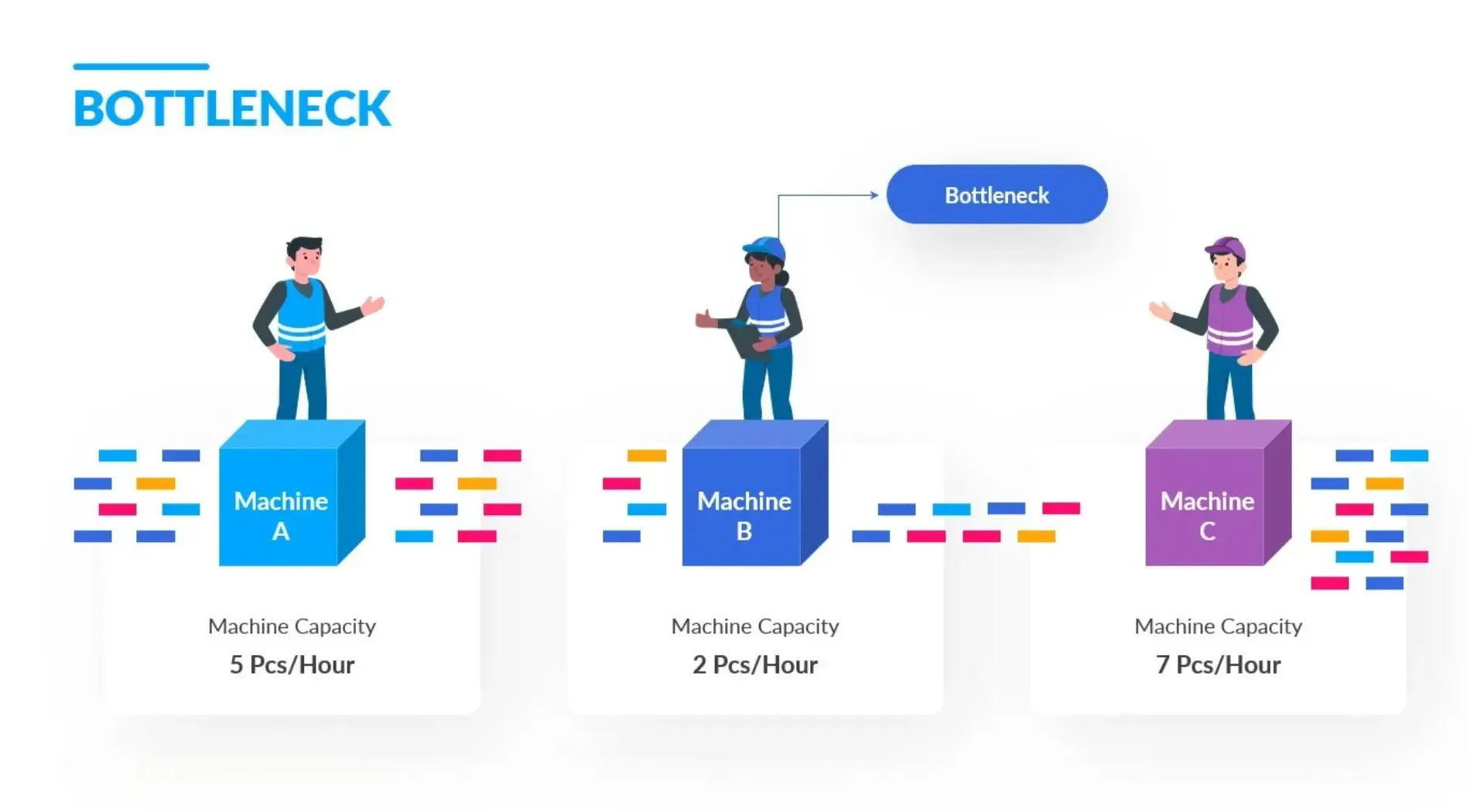
Phân loại các Bottleneck
Trong hạ tầng công nghệ và máy tính, bottleneck được phân rõ theo thành phần phần cứng hoặc phần mềm đang kìm hãm hiệu năng:
- Điểm nghẽn bộ vi xử lý (CPU Bottleneck): Xảy ra khi năng lực tính toán bị quá tải bởi quá nhiều tiến trình chạy song song, làm kéo chậm toàn bộ tác vụ từ phản hồi ứng dụng cho đến các lệnh chạy ngầm.
- Điểm nghẽn bộ nhớ RA (RAM Bottleneck): Xuất hiện khi dung lượng RAM bị cạn kiệt, buộc máy chủ phải dùng ổ cứng làm bộ nhớ ảo tạm thời (swapping) khiến tốc độ truy xuất tụt dốc không phanh.
- Điểm nghẽn lưu trữ (Disk I/O Bottleneck): Khóa chặt các thao tác ghi dữ liệu, tải tệp tin hoặc sao lưu các tập dữ liệu khổng lồ khi tốc độ đọc/ghi vật lý của ổ cứng chạm ngưỡng kịch trần.
- Điểm nghẽn mạng lưới (Network Bottleneck): Phát sinh khi băng thông đường truyền eo hẹp không đủ để luân chuyển dữ liệu, gây ra hiện tượng trễ mạng (latency), mất kết nối hoặc lỗi quá thời gian chờ.
- Điểm nghẽn cơ sở dữ liệu (Database Bottleneck): Khởi phát từ các câu lệnh truy vấn cấu hình kém hoặc các bảng dữ liệu bị khóa do lưu lượng truy cập ồ ạt, làm tê liệt các tính năng cần truy xuất dữ liệu theo thời gian thực.
- Điểm nghẽn mã nguồn (Software Bottleneck): Bắt nguồn từ mã lập trình bị lỗi, thuật toán kém tối ưu hoặc tham số cấu hình sai lệch; bóp nghẹt toàn bộ hiệu năng bất kể phần cứng máy chủ bên dưới có mạnh đến đâu.
- Điểm nghẽn xử lý đồng thời (Concurrency Bottleneck): Xảy ra khi ứng dụng bất lực trong việc điều phối và đồng bộ nhiều luồng dữ liệu (threads) cùng lúc, gây tranh chấp tài nguyên nghiêm trọng khi lượng người dùng bùng nổ.
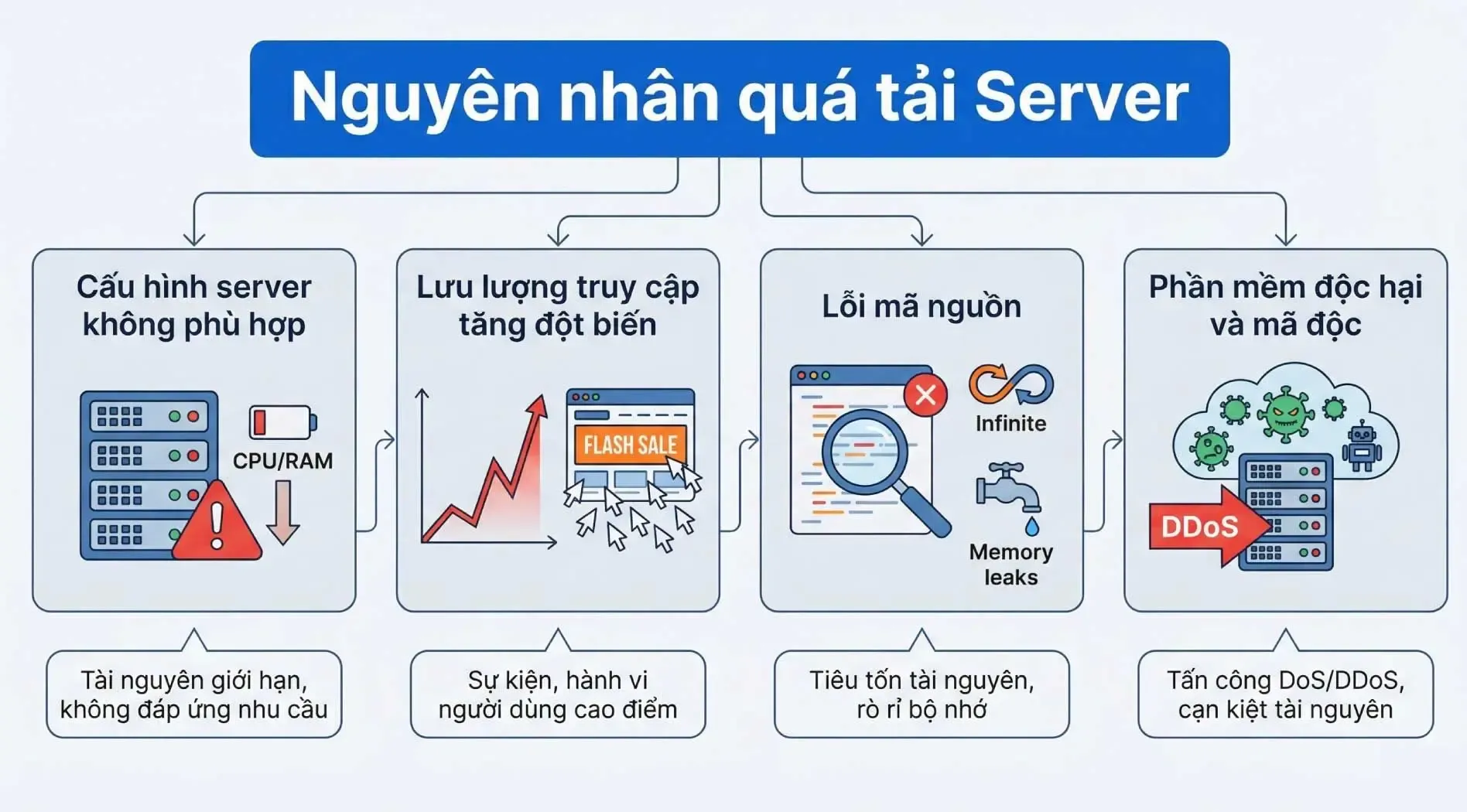
Nguyên nhân gây ra tình trạng Bottleneck
Bottleneck hình thành khi nhu cầu xử lý vượt quá năng lực đáp ứng của một thành phần cụ thể trong hệ thống. Có năm nguyên nhân chính:
Giới hạn phần cứng
CPU ít lõi, RAM thấp hoặc ổ cứng cơ học (HDD) đời cũ tạo ra ngưỡng giới hạn cứng về hiệu năng. Khi lưu lượng tăng, các thành phần này bị vắt kiệt công suất trước, khiến hệ thống phản hồi chậm chạp, rơi vào trạng thái đóng băng hoặc ngừng hoạt động hoàn toàn.
Mã nguồn và thuật toán thiếu tối ưu
Việc lạm dụng các vòng lặp vô hạn, xây dựng thuật toán có độ phức tạp tính toán cao hoặc duy trì các lệnh gọi hàm không cần thiết sẽ tiêu tốn CPU và RAM một cách vô ích. Điều này tước đoạt tài nguyên của các tác vụ cốt lõi, ngay cả khi phần cứng vẫn còn dư thừa công suất.
Truy vấn database kém hiệu quả
Câu lệnh SQL thực hiện Full Table Scan (quét toàn bộ bảng) thay vì dùng Index buộc hệ thống lục tìm thủ công trên hàng triệu dòng dữ liệu. Khi hàng nghìn người dùng truy vấn đồng thời, thời gian phản hồi API kéo dài và database nhanh chóng trở thành điểm nghẽn.
Cấu hình hệ thống sai lệch
Giới hạn kết nối đồng thời quá thấp, phân bổ dung lượng bộ nhớ đệm không hợp lý hoặc để thời gian chờ quá ngắn tạo ra các rào cản nhân tạo. Máy chủ chưa dùng hết công suất vật lý nhưng vẫn trả về lỗi vì các tham số cấu hình không tương thích với quy mô tải thực tế.
Cân bằng tải kém
Khi bộ định tuyến dồn toàn bộ lưu lượng vào một máy chủ, hiện tượng quá tải cục bộ sẽ lập tức xảy ra. Máy chủ phải gồng gánh luồng traffic sẽ trở thành một Bottleneck, trong khi tổng thể hạ tầng vẫn còn nhiều năng lực chưa được khai thác.
Tác động của Bottleneck đối với doanh nghiệp
Khi xuất hiện trên hạ tầng công nghệ, Bottleneck gây ra những hệ lụy dây chuyền lên hiệu suất vận hành và lợi ích kinh tế của doanh nghiệp:
- Tổn thất doanh thu: Điểm nghẽn tại Disk I/O hay database làm tê liệt quy trình thanh toán, hệ thống trả lỗi liên tục và doanh thu bốc hơi theo từng phút trong khi khách hàng chuyển sang đối thủ.
- Lãng phí ngân sách: Khi không tìm ra nguyên nhân gốc rễ, doanh nghiệp thường chọn cách nâng cấp cấu hình máy chủ một cách mù quáng, làm leo thang hóa đơn đám mây hàng tháng nhưng không giải quyết được điểm nghẽn.
- Phát sinh chi phí "chữa cháy" và trì trệ tiến độ dự án: Khi Bottleneck xảy ra vào giờ cao điểm, đội ngũ lập trình viên và DevOps phải dừng mọi công việc hiện tại để tập trung vá lỗi khẩn cấp, làm tốn chi phí vận hành, chậm tiến độ ra mắt các tính năng mới và bỏ lỡ các cơ hội kinh doanh quan trọng.
- Gây ứ đọng dữ liệu và tê liệt hệ thống báo cáo: Luồng dữ liệu bị tắc khiến thông tin từ các bộ phận không thể đồng bộ về data center đúng hạn, báo cáo theo thời gian thực bị sai lệch và quyết định trên dữ liệu của nhà quản lý ra không còn phản ánh thực tế.

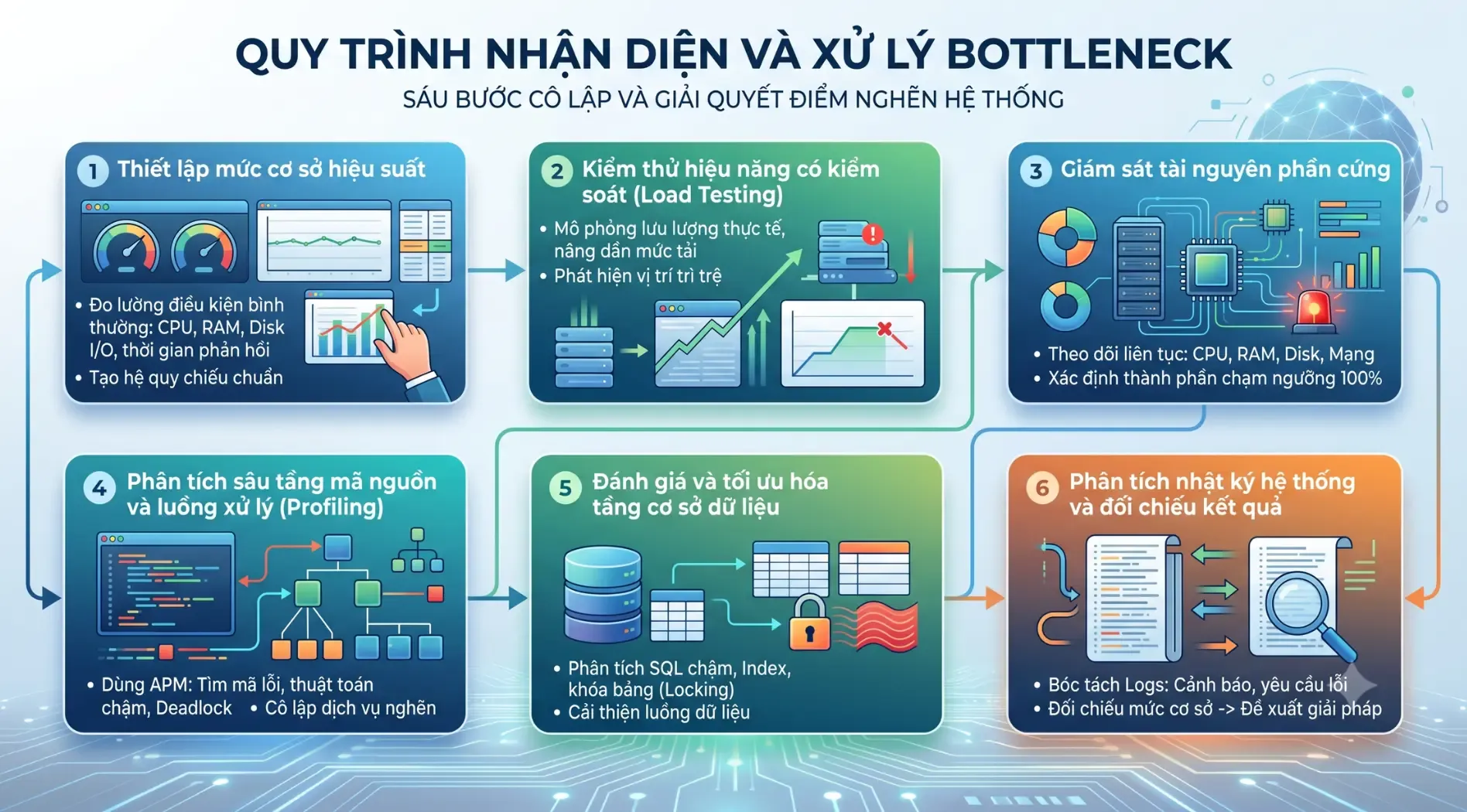
Các bước nhận diện để xử lý Bottleneck
Để xử lý Bottleneck hiệu quả, kỹ sư cần kiểm tra hệ thống theo quy trình có cấu trúc, từ đo hiệu suất nền đến phân tích tài nguyên, mã nguồn và cơ sở dữ liệu. Các bước cơ bản gồm:
1. Thiết lập mức hiệu suất cơ sở
Trước tiên, cần ghi nhận trạng thái hoạt động bình thường của hệ thống thông qua các chỉ số như Response Time, CPU, RAM, Disk I/O, băng thông mạng và tốc độ truy vấn cơ sở dữ liệu. Đây là mốc tham chiếu quan trọng để phát hiện bất thường khi hệ thống chậm hoặc quá tải.
2. Thực hiện kiểm thử hiệu năng
Kỹ sư có thể dùng các công cụ như JMeter, LoadRunner hoặc Gatling để mô phỏng lưu lượng truy cập thực tế. Khi tăng dần tải từ mức nhẹ đến cực hạn, hệ thống sẽ bộc lộ điểm bắt đầu suy giảm hiệu suất, từ đó giúp xác định giới hạn chịu tải và khu vực có nguy cơ Bottleneck.
3. Giám sát tài nguyên phần cứng
Trong quá trình kiểm thử, cần theo dõi liên tục CPU, RAM, ổ cứng và băng thông mạng. Nếu một tài nguyên thường xuyên chạm ngưỡng cao bất thường, chẳng hạn CPU 100%, RAM cạn, Disk I/O tăng mạnh hoặc mạng nghẽn, đó có thể là điểm nghẽn chính cần xử lý.
4. Phân tích mã nguồn và luồng xử lý
Ở tầng ứng dụng, các công cụ APM giúp phát hiện hàm xử lý chậm, thuật toán kém tối ưu, Thread Contention hoặc Deadlock. Bước này cho phép kỹ sư xác định chính xác đoạn code, API hoặc microservice đang làm giảm thông lượng của toàn hệ thống.
5. Kiểm tra và tối ưu cơ sở dữ liệu
Cơ sở dữ liệu thường là nguyên nhân phổ biến gây Bottleneck. Kỹ sư cần rà soát Slow Query Logs, Execution Plan, Connection Pool, Index và tình trạng Lock Contention để phát hiện truy vấn chậm, bảng thiếu chỉ mục hoặc luồng dữ liệu bị khóa nghẽn.
6. Phân tích log và đối chiếu kết quả
Cuối cùng, cần kiểm tra log hệ thống để tìm lỗi Timeout, request thất bại, cảnh báo ẩn hoặc các bất thường không hiển thị rõ trên dashboard giám sát. Sau đó, đối chiếu dữ liệu với mức hiệu suất cơ sở để xác định thời điểm, nguyên nhân và giải pháp tối ưu phù hợp.
Tóm lại, việc chủ động kiểm thử, giám sát hệ thống và nắm rõ quy trình nhận diện Bottleneck là gì giúp doanh nghiệp bảo vệ toàn vẹn hiệu suất ứng dụng và tối ưu hóa chi phí đầu tư. Để hiện thực hóa một hạ tầng vững chắc, không còn nỗi lo nghẽn mạng, cạn kiệt RAM hay kịch trần Disk I/O, hệ sinh thái VNPT Cloud chính là giải pháp nâng cấp toàn diện cho doanh nghiệp.