VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



Distributed Tracing là gì? Nhìn rõ hành trình của một request


Trong kỷ nguyên của Microservices, một thao tác đơn giản của người dùng có thể đi qua hàng chục dịch vụ khác nhau. Khi xảy ra lỗi hoặc hệ thống chạy chậm, việc tìm ra "thủ phạm" giống như mò kim đáy bể. Đó là lúc Distributed Tracing (Truy vết phân tán) trở thành chìa khóa vạn năng cho các kỹ sư DevOps và SRE.
1. Distributed Tracing là gì?
Distributed Tracing là phương pháp theo dõi và quan sát các yêu cầu (requests) khi chúng di chuyển qua các hệ thống phân tán phức tạp. Thay vì chỉ xem nhật ký (logs) của một ứng dụng đơn lẻ, truy vết phân tán cho bạn một cái nhìn toàn cảnh về con đường mà yêu cầu đã đi qua, từ giao diện người dùng đến các dịch vụ hậu cần và cơ sở dữ liệu.
Đây là một trong ba trụ cột quan trọng của Observability (tính quan sát), bên cạnh Metrics và Logs, giúp kết nối các sự kiện rời rạc thành một câu chuyện có bối cảnh cụ thể.
2. Ví dụ về truy vết phân tán Distributed Tracing
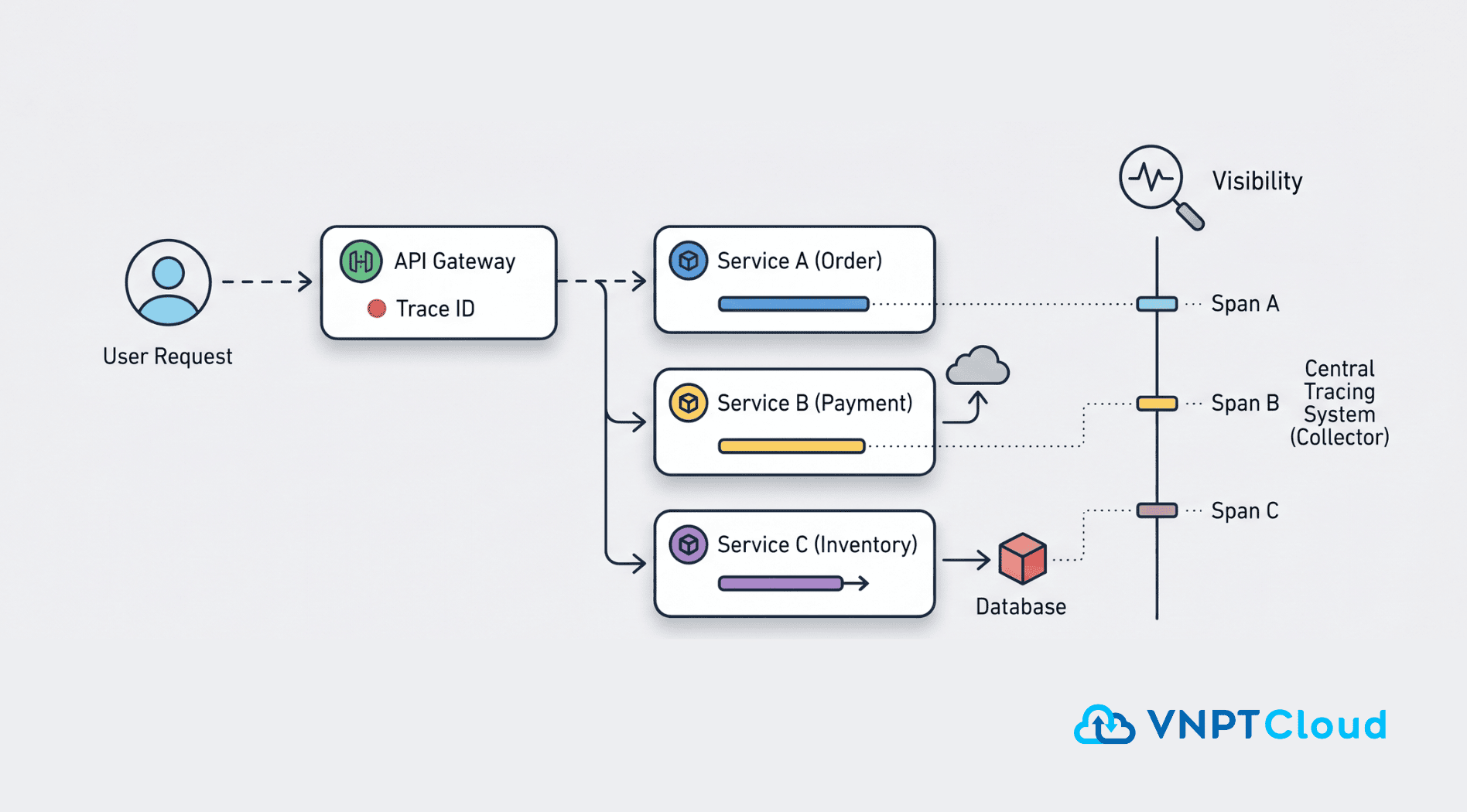
Hãy tưởng tượng một khách hàng thực hiện đặt hàng trên ứng dụng thương mại điện tử:
- Request đầu tiên gửi đến Dịch vụ đặt hàng.
- Dịch vụ đặt hàng gọi đến Dịch vụ thanh toán.
- Dịch vụ thanh toán gọi đến API Ngân hàng.
- Đồng thời, Dịch vụ đặt hàng gọi Dịch vụ kho để kiểm tra tồn kho.
Nếu bước thanh toán bị chậm, Distributed Tracing sẽ hiển thị một biểu đồ dạng "thác nước" (waterfall chart). Bạn sẽ thấy ngay lập tức API Ngân hàng mất 5 giây để phản hồi, trong khi các dịch vụ nội bộ chỉ mất vài mil giây.
3. Cách hoạt động của Distributed Tracing
Distributed Tracing hoạt động dựa trên việc gắn thẻ và ghi lại hành trình:
- Trace ID: Khi một request bắt đầu, hệ thống tạo ra một ID duy nhất cho toàn bộ hành trình.
- Span: Mỗi công việc tại một dịch vụ cụ thể được gọi là một "Span". Mỗi Span chứa thông tin về thời gian bắt đầu, kết thúc và các metadata.
- Context Propagation: Trace ID được truyền đi xuyên suốt qua các lời gọi HTTP hoặc Message Queue giữa các dịch vụ để liên kết các Span lại với nhau.
4. Lợi ích Distributed Tracing mang lại
Việc triển khai truy vết phân tán mang lại những giá trị vượt trội cho doanh nghiệp:
- Giảm chỉ số MTTR (Mean Time To Resolution): Phát hiện và cô lập nguyên nhân gốc rễ của sự cố trong vài phút thay vì vài giờ.
- Tối ưu hóa hiệu suất: Xác định các điểm nghẽn (bottlenecks) và các dịch vụ có độ trễ cao để cải thiện tốc độ hệ thống.
- Hiểu rõ sự phụ thuộc: Giúp các nhà phát triển hình dung được mối quan hệ phức tạp giữa các dịch vụ trong hệ thống Microservices.
- Cải thiện trải nghiệm người dùng: Đảm bảo các giao dịch diễn ra mượt mà và giảm thiểu tỷ lệ lỗi không mong muốn.
5. Thách thức của Distributed Tracing
Dù mạnh mẽ, nhưng Distributed Tracing cũng đi kèm với một số khó khăn:
- Chi phí triển khai: Đòi hỏi phải thay đổi mã nguồn hoặc cài đặt thêm các Agent (tác nhân) vào tất cả các dịch vụ.
- Lưu lượng dữ liệu lớn: Việc ghi lại mọi request có thể tạo ra một lượng dữ liệu khổng lồ, gây tốn kém chi phí lưu trữ.
- Độ phức tạp: Cần có sự đồng bộ về giao thức truyền context giữa các nhóm phát triển khác nhau.
6. Khi nào doanh nghiệp cần Distributed Tracing?
Doanh nghiệp của bạn nên cân nhắc triển khai Distributed Tracing khi:
- Đang chuyển dịch từ kiến trúc Monolithic sang Microservices hoặc Serverless.
- Hệ thống thường xuyên gặp các lỗi khó tái hiện hoặc độ trễ không ổn định mà Logs thông thường không giải thích được.
- Cần nâng cao khả năng quan sát (Observability) để đáp ứng các cam kết về chất lượng dịch vụ (SLA).
7. Câu hỏi thường gặp về Distributed Tracing
Q: Distributed Tracing có thay thế được Logging không?
- A: Không. Tracing giúp bạn biết lỗi ở đâu, còn Logging cho bạn biết chi tiết những gì đã xảy ra tại một thời điểm cụ thể trong dịch vụ đó.
Q: Có những công cụ Distributed Tracing phổ biến nào?
- A: Các công cụ phổ biến bao gồm Jaeger, Zipkin, AWS X-Ray, và các giải pháp thương mại tích hợp cùng APM như VNPT APM hay Dynatrace.
Q: Làm sao để giảm chi phí lưu trữ dữ liệu Trace?
- A: Kỹ thuật "Sampling" (Lấy mẫu) thường được sử dụng để chỉ ghi lại một tỷ lệ phần trăm các request thay vì toàn bộ.