VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



[Bách khoa Big Data] Kiến trúc Lambda là gì? Cách thức vận hành của kiến trúc Lambda


Trong bài viết này, chúng ta sẽ thảo luận về Kiến trúc Lambda trong Big Data. Ngoài ra, chúng ta cũng tìm hiểu về các ứng dụng, ưu điểm cũng như nhược điểm của Kiến trúc Lambda; đồng thời đi sâu vào chi tiết cách thức vận hành của nó.
Kiến trúc Lambda là gì?
Đây là một kiến trúc dữ liệu lớn thế hệ mới, được thiết kế để nạp và xử lý dữ liệu, đồng thời cho phép truy vấn cả dữ liệu mới (fresh data) và dữ liệu lịch sử (batch data) trong cùng một hệ thống kiến trúc duy nhất.
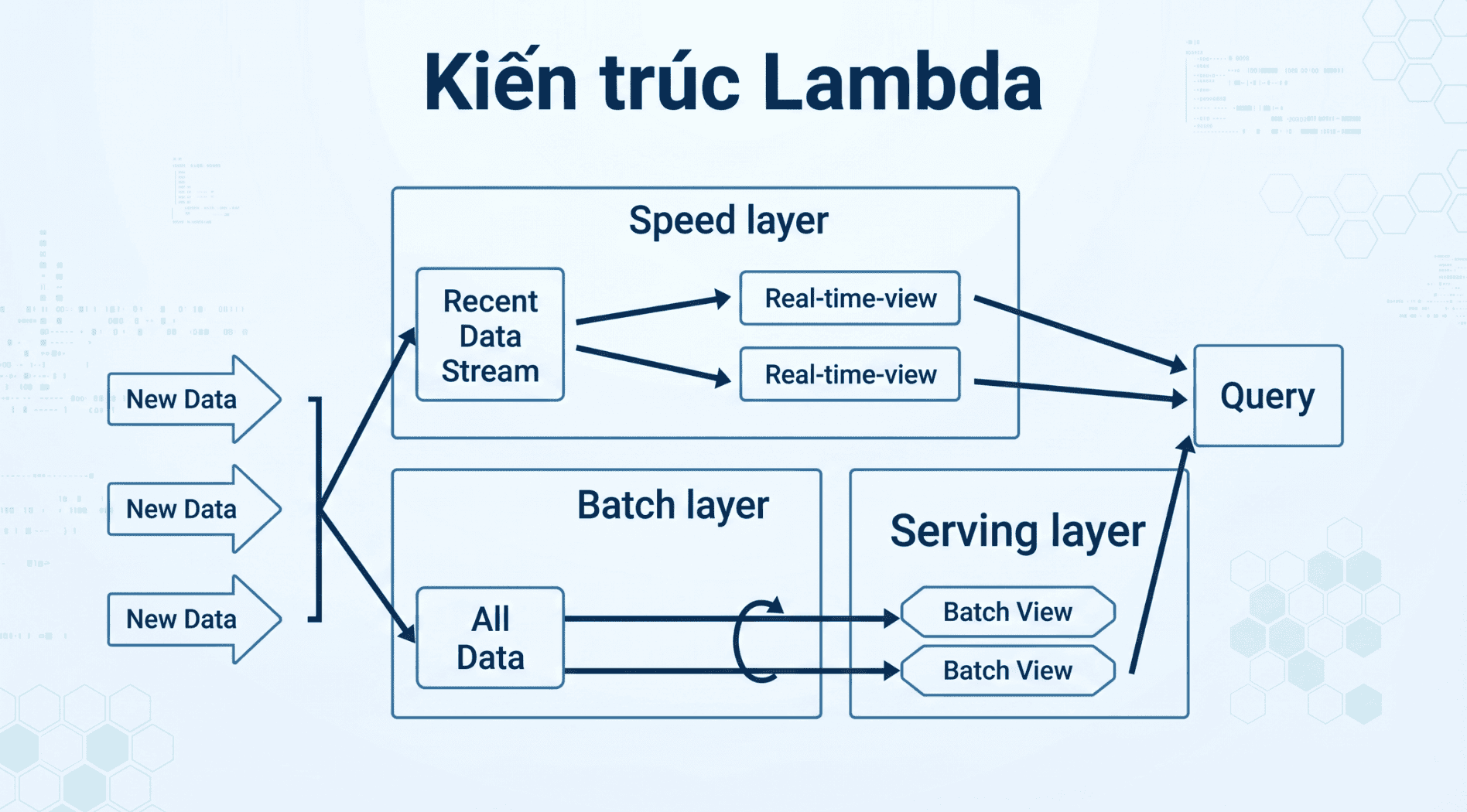
Chúng ta sử dụng kiến trúc này để giải quyết vấn đề tính toán các hàm tùy ý (arbitrary functions). Kiến trúc này bao gồm ba lớp (layers):
- Lớp Batch (Batch layer)
- Lớp Phục vụ (Serving layer)
- Lớp Tốc độ (Speed layer)
Về cơ bản, chúng ta thường gọi Lớp Batch là một hệ thống "hồ dữ liệu" (data lake) như Hadoop. Lớp này sử dụng kho lưu trữ lịch sử để giữ lại tất cả dữ liệu đã từng được thu thập. Hơn nữa, lớp này hỗ trợ các truy vấn hàng loạt (batch query) và sử dụng xử lý lô để tạo ra các báo cáo phân tích hoặc truy vấn đặc thù (ad-hoc).
Thứ hai, Lớp Tốc độ là sự kết hợp của xếp hàng tin nhắn (queuing) và dòng chảy dữ liệu (streaming). Lớp tốc độ tương tự như lớp batch ở chỗ nó tính toán các chỉ số phân tích tương ứng, ngoại trừ việc nó tính toán theo thời gian thực và chỉ dựa trên những dữ liệu mới nhất.
Ví dụ: Các phân tích mà lớp batch tính toán có thể dựa trên dữ liệu đã cũ hơn 1 giờ. Khi đó, lớp tốc độ có trách nhiệm tính toán các phân tích thời gian thực dựa trên luồng dữ liệu di chuyển nhanh có độ tuổi từ 0 đến 1 giờ.
Lớp thứ ba – Lớp Phục vụ, có nhiệm vụ trả về kết quả truy vấn, được kết hợp từ cả lớp tốc độ và lớp batch.
Cách thức vận hành của Kiến trúc Lambda
a. Khi tất cả dữ liệu đi vào hệ thống, chúng sẽ được gửi đồng thời đến cả Lớp Batch và Lớp Tốc độ để xử lý.
b. Lớp Batch có hai chức năng quan trọng nhất:
- Quản lý bộ dữ liệu gốc (master dataset).
- Tính toán trước các khung nhìn lô (batch views).
c. Lớp Phục vụ được dùng để lập chỉ mục (index) các khung nhìn lô, nhờ đó chúng có thể được truy vấn với độ trễ thấp và theo cách thức tùy biến (ad-hoc).
d. Lớp Tốc độ bù đắp cho độ trễ cao của các bản cập nhật từ lớp phục vụ, chỉ xử lý dữ liệu mới nhất.
e. Chúng ta có thể trả lời bất kỳ truy vấn nào bằng cách hợp nhất (merge) các kết quả từ khung nhìn lô (batch views) và khung nhìn thời gian thực (real-time views).
Các ứng dụng điển hình của Lambda
Đây là một mô hình mới nổi trong tính toán Dữ liệu lớn. Các trường hợp sử dụng phổ biến bao gồm việc nạp nhật ký (log ingestion) và các phân tích đi kèm.
Các thông điệp nhật ký thường được tạo ra với tốc độ rất cao và có tính chất bất biến (không thay đổi). Chúng ta có thể gọi đây là "dữ liệu nhanh" (fast data). Việc nạp mỗi thông điệp nhật ký không yêu cầu phản hồi ngay lập tức từ thực thể gửi dữ liệu; đây là một đường ống dữ liệu một chiều.
Ví dụ: Phân tích nhật ký nhấp chuột (click logs) trên website để đếm lượt truy cập trang và độ phổ biến của trang web.
Ưu điểm của Kiến trúc Lambda
- Nhấn mạnh vào việc giữ nguyên dữ liệu đầu vào không thay đổi và kỷ luật trong việc mô hình hóa quá trình chuyển đổi dữ liệu.
- Giúp các quy trình làm việc (workflows) lớn trên MapReduce trở nên dễ kiểm soát hơn, vì nó cho phép bạn gỡ lỗi (debug) từng giai đoạn một cách độc lập.
- Làm nổi bật vấn đề tái xử lý dữ liệu (reprocessing) – một trong những thách thức then chốt của xử lý dòng chảy. Quá trình này giúp tính toán lại dữ liệu đầu vào để đưa ra kết quả mới khi mã nguồn thay đổi (một yêu cầu hiển nhiên nhưng thường bị bỏ qua).
Nhược điểm của Kiến trúc Lambda
- Vấn đề bảo trì mã nguồn: Bạn cần duy trì mã nguồn để tạo ra cùng một kết quả trên hai hệ thống phân tán phức tạp khác nhau. Điều này thực sự rất khó khăn. Việc lập trình trên các khung làm việc như Storm và Hadoop rất phức tạp, mã nguồn thường bị phụ thuộc quá nhiều vào khung làm việc mà nó chạy trên đó.
- Câu hỏi đặt ra là: Tại sao hệ thống xử lý dòng chảy không được cải thiện để xử lý toàn bộ bài toán trong miền mục tiêu của nó? Để khắc phục điều này, một hướng tiếp cận là sử dụng một ngôn ngữ hoặc khung làm việc trừu tượng hóa cả thực tế thời gian thực và xử lý lô (ví dụ như "Summingbird"). Điều này giúp viết mã ở cấp độ cao hơn rồi sau đó mới "biên dịch" xuống xử lý dòng chảy hoặc MapReduce. Tuy nhiên, phương pháp này chỉ cải thiện một chút chứ chưa giải quyết triệt để vấn đề.
Kết luận
Chúng ta đã nghiên cứu về định nghĩa, cách vận hành, ứng dụng, ưu điểm và hạn chế của Kiến trúc Lambda. Hy vọng kiến thức về kiến trúc dữ liệu lớn mới này sẽ giúp bạn hiểu rõ hơn về các khái niệm vận hành của nó.








