VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



Kubernetes – 10 năm, vẫn còn nhiều việc phải làm


Kubernetes ra mắt vào tháng 6 năm 2014 – từ đó, nó đã đóng một vai trò quan trọng trong việc phổ biến các thiết kế ứng dụng theo hướng đám mây (Cloud-Native) và hỗ trợ triển khai microservices nhiều hơn. Sự phát triển của việc triển khai Container là rất lớn, và Kubernetes là công cụ không thể thiếu để các công ty quản lý khi triển khai theo cách này – theo báo cáo mới nhất của CNCF, 84% tổ chức đang sử dụng hoặc đánh giá cao về Kubernetes, trong khi 66% người tiêu dùng tiềm năng và thực tế đang sử dụng Kubernetes trong môi trường sản xuất.
Ngày nay, Kubernetes không chỉ đơn thuần là một công cụ điều phối Container. Nó đã trở thành một nền tảng để xây dựng các nền tảng khác. API hợp nhất giúp Kubernetes trở thành một công cụ tuyệt vời để chạy các khối lượng công việc trên nhiều đám mây và trong các môi trường lai (nơi kết hợp cả hạ tầng nội bộ onprimes và đám mây công cộng cloud public), giúp các doanh nghiệp tránh bị “khóa” vào một nhà cung cấp. Điều này mang lại sự linh hoạt trong các quyết định kiến trúc và giảm đáng kể chi phí hạ tầng (cụ thể là các hóa đơn dịch vụ cloud).
Tốc độ tăng trưởng hàng năm đã tạo ra sự tất yếu, xu hướng của Kubernetes trong mỗi tổ chức chỉ trong một thời gian ngắn.
Câu hỏi đặt ra là – Kubernetes sẽ ra sao? Liệu tất cả các vấn đề đã được giải quyết?
Độ phức tạp của cơ sở dữ liệu
Trong lĩnh vực cơ sở dữ liệu, nhiều nhóm cộng đồng đã bắt đầu tham gia vào Kubernetes để đánh giá cách nó có thể hoạt động với các dự án của họ, và ngược lại, cách họ có thể triển khai các dự án để chạy trên Kubernetes. Những câu hỏi chính mà các cộng đồng này muốn trả lời xoay quanh các thách thức đang tồn tại trong việc chạy cơ sở dữ liệu trên Kubernetes, cũng như chia sẻ các phương pháp tốt nhất cho việc triển khai ban đầu và các bước tối ưu hóa hiệu suất.
Khởi đầu gặp nhiều khó khăn. Với các phiên bản đầu tiên của StatefulSets và Persistent Volumes, các kỹ sư đã có thể chạy các workloads có trạng thái trong Kubernetes. Nhưng bắt đầu một cơ sở dữ liệu và duy trì nó hoạt động tốt là hai thách thức khác nhau. Sự phức tạp của việc chạy cơ sở dữ liệu trong K8s vẫn còn nhiều điều chưa hiểu rõ. Điều đó dẫn đến những giả định sai lầm rằng Kubernetes chỉ dành cho các workloads không có trạng thái.
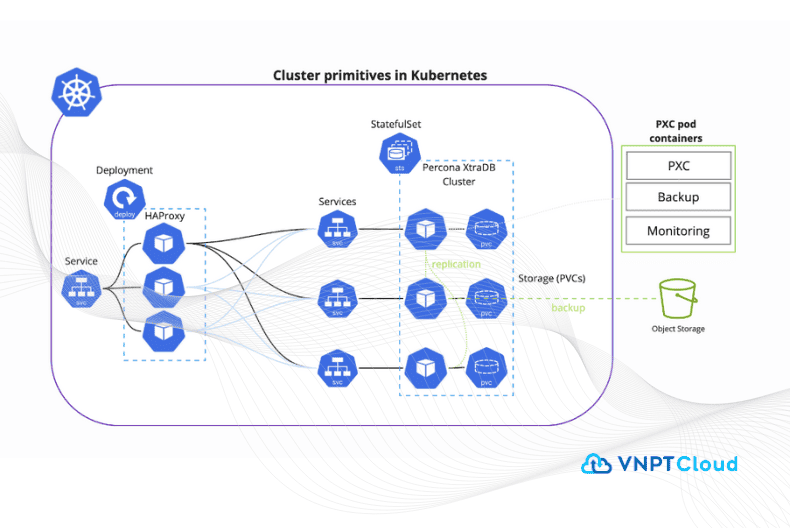
Nhưng may mắn thay, sự tò mò, nghiên cứu của các kỹ sư chưa bao giờ dừng lại. Các giao diện lưu trữ container (Container Storage Interfaces) đã phát triển, cung cấp cho các quản trị viên sự kiểm soát lưu trữ tốt hơn nhiều. Và với sự ra mắt của Kubernetes Operators, các nhà phát triển đã có thể đơn giản hóa đáng kể việc triển khai và quản lý các ứng dụng phức tạp (như cơ sở dữ liệu).
Bằng cách giúp chạy các cơ sở dữ liệu như PostgreSQL, MySQL và MongoDB trong container dễ dàng hơn - dưới dạng các triển khai dữ liệu cloud-native, nhiều nhà phát triển đã có thể áp dụng các phương pháp tiếp cận ứng dụng cloud-native nói chung. Sự chuyển đổi này đã mang lại nhiều giá trị hơn và nhiều cơ hội hơn cho các công ty – theo cộng đồng Data on Kubernetes, 83% công ty được khảo sát đã nhận thấy hơn 10% doanh thu của họ đến từ việc chạy dữ liệu trên Kubernetes, và 1/3 các tổ chức đã thấy năng suất của họ tăng gấp đôi. Những công ty này hiện đang chạy các khối lượng công việc phức tạp hơn trên Kubernetes, bao gồm phân tích dữ liệu (67%) và AI/ML (50%).
Vấn đề của Operators
Các Operators - người vận hành, vận hành chắc chắn đã đơn giản hóa việc triển khai cơ sở dữ liệu, nhưng quan trọng hơn là những gì chúng đã làm – là loại bỏ nhu cầu thực hiện các tác vụ lặp lại và giảm thiểu khả năng xảy ra lỗi do con người.
Nhưng không phải tất cả các vấn đề đều đã được giải quyết.
Sự phức tạp
Các toán tử trừu tượng hóa các nguyên hàm Kubernetes và loại bỏ nhu cầu cấu hình cơ sở dữ liệu. Nhưng điều này không loại bỏ hoàn toàn sự phức tạp, vẫn yêu cầu các kỹ sư kết nối với Kubernetes và tương tác với kubectl để khắc phục sự cố hoặc thực hiện các tác vụ vận hành khác nhau.
Đa đám mây
Như đã đề cập ở trên, Kubernetes trừu tượng hóa hạ tầng và cung cấp một API hợp nhất. Điều đó làm cho nó trở thành một công cụ lý tưởng để xây dựng các nền tảng đa đám mây và đám mây lai. Nhưng đồng thời câu chuyện đa đám mây vẫn chưa hoàn thiện. Đã có những nỗ lực để giải quyết việc triển khai đa cụm thông qua Federation (KubeFed nổi tiếng đã bị loại bỏ), và các dự án đang diễn ra như Elotl Nova hoặc Karmada.
Việc thiếu một giải pháp thống nhất buộc các kỹ sư phải tạo ra các cách riêng để cung cấp khả năng đa cụm. Chẳng hạn, tất cả các Percona Operators cho phép người dùng thiết lập sao chép giữa các cụm cơ sở dữ liệu, nhưng việc phát hiện lỗi và chuyển đổi dự phòng vẫn là thủ công.
Đa cơ sở dữ liệu
Theo Redgate, 79% các công ty sử dụng hai hoặc nhiều công nghệ cơ sở dữ liệu trong stack của họ. Áp dụng điều này vào Kubernetes, nó sẽ yêu cầu chạy một Operator cho mỗi công nghệ cơ sở dữ liệu. Mỗi Operator đi kèm với các mẫu cấu hình riêng của nó. Điều này một lần nữa làm tăng sự phức tạp và gánh nặng vận hành.

Tương lai: Nhìn xa hơn Operators
Trong tương lai, chúng ta kỳ vọng sẽ thấy một cấp độ trừu tượng mới, giúp người dùng chiến đấu với sự phức tạp của các vấn đề đã liệt kê ở trên. Chúng tôi dự đoán rằng sẽ có nhiều giải pháp mã nguồn mở xuất hiện dưới dạng các ứng dụng web hoặc API mới. Đây là sức mạnh của phần mềm mã nguồn mở – xây dựng các giải pháp như Kubernetes và sau đó làm cho chúng tốt hơn.
Percona là một ví dụ về một công ty đang cố gắng giải quyết trực tiếp các vấn đề về sự phức tạp, đa đám mây và đa cơ sở dữ liệu. Họ đã ra mắt Percona Everest, một nền tảng cơ sở dữ liệu cloud-native mã nguồn mở cung cấp trải nghiệm click-and-run để chạy và quản lý cơ sở dữ liệu trên Kubernetes. Điều làm cho Percona Everest trở nên độc đáo và là một công cụ đáng thử là trong một nền tảng chúng tôi đang giải quyết các vấn đề đã nêu ở trên.
Percona Everest đơn giản hóa sự phức tạp vốn có của Kubernetes và chính các Operators bằng cách cung cấp một giao diện đồ họa thân thiện với người dùng và một API mạnh mẽ. Điều này giải quyết trực tiếp các thách thức của việc khắc phục sự cố và quản lý Kubernetes. Họ loại bỏ sự phức tạp của việc triển khai cơ sở dữ liệu đa đám mây bằng cách hợp lý hóa việc điều phối nhiều Operators trên các cụm Kubernetes khác nhau. Điều này biến việc sao chép đa vùng và liên khu vực từ một câu đố YAML thành một trải nghiệm click-and-configure đơn giản.
Tóm lại, khi chúng ta thấy ngày càng nhiều công ty áp dụng Kubernetes, chúng ta sẽ tiếp tục khám phá những cách thức để cải thiện quy trình làm việc, tiết kiệm thời gian cho nhà phát triển và giảm thiểu chi phí cho công ty.