VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



Data Warehouse Là Gì? Kiến trúc, phân loại và lợi ích của kho dữ liệu


Data Warehouse là gì là câu hỏi thường gặp khi doanh nghiệp bắt đầu xây dựng hệ thống phân tích dữ liệu. Bên cạnh Data Warehouse, các khái niệm như Database, Data Lake và Data Lakehouse cũng cần được phân biệt rõ để chọn đúng mô hình lưu trữ, xử lý và khai thác dữ liệu.
Data Warehouse Là Gì?
Data Warehouse (Kho dữ liệu) là một hệ thống lưu trữ dữ liệu trung tâm, làm nhiệm vụ tổng hợp thông tin từ nhiều nguồn khác nhau và được tối ưu hóa đặc biệt cho mục đích truy vấn, phân tích.
Hệ thống này thường ứng dụng các quy trình ETL (Trích xuất, Chuyển đổi và Tải) hoặc ELT (Trích xuất, Tải và Chuyển đổi) để làm sạch và tổ chức dữ liệu. Mục tiêu cuối cùng là phục vụ cho hệ thống Trí tuệ doanh nghiệp (Business Intelligence - BI) và các hoạt động phân tích dữ liệu chuyên sâu.

Cách hoạt động của Data Warehouse
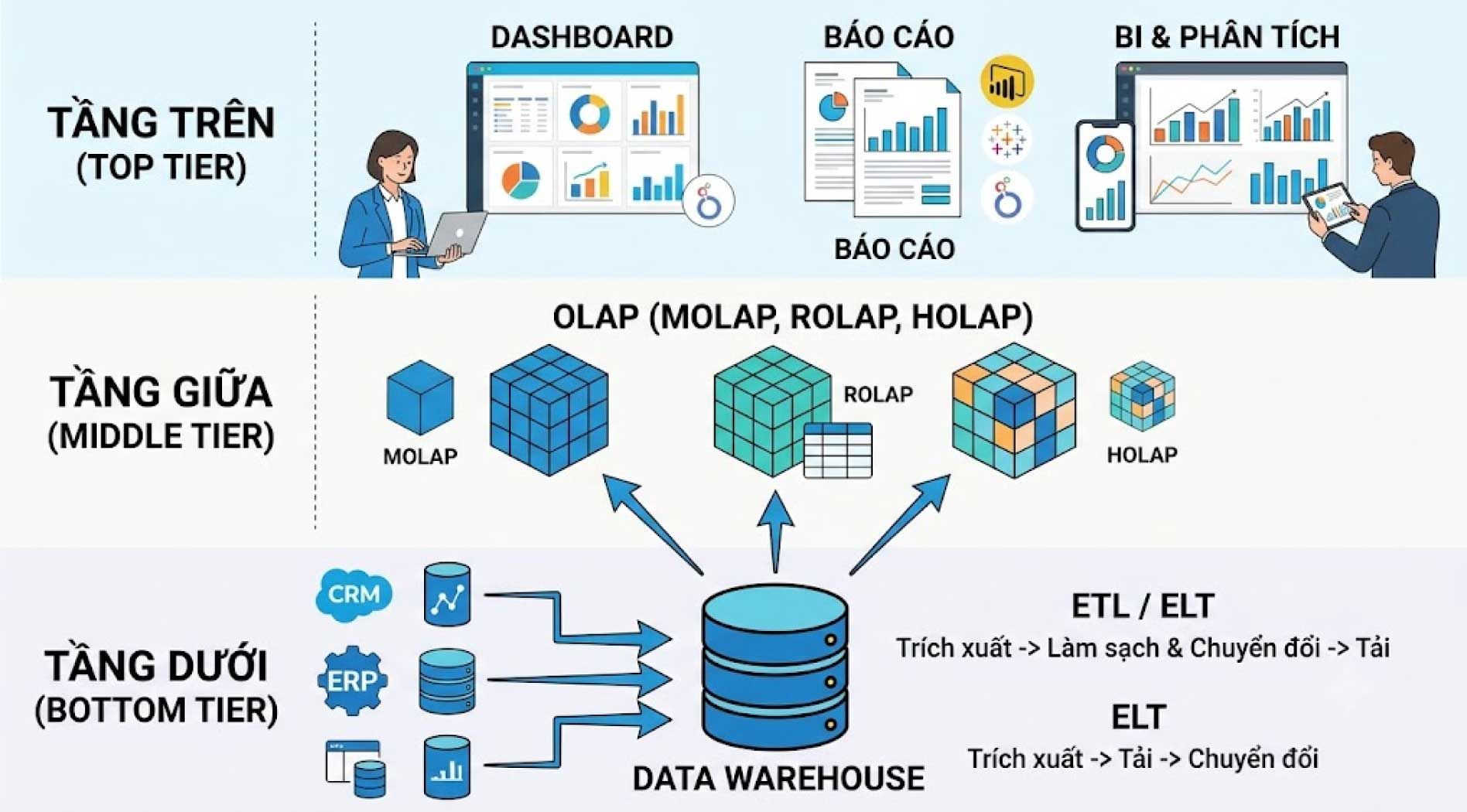
Một kho dữ liệu tiêu chuẩn được thiết kế theo kiến trúc 3 tầng nhằm tối ưu hóa quá trình chuyển đổi dữ liệu:
Tầng Dưới (Bottom Tier): Tích hợp dữ liệu
Ở tầng này, dữ liệu thường được xử lý qua quy trình ETL hoặc ELT. Với ETL, dữ liệu được làm sạch và chuyển đổi trước khi tải vào kho. Với ELT, dữ liệu được tải vào trước rồi mới chuyển đổi sau, phù hợp hơn với một số hệ thống hiện đại có khả năng xử lý dữ liệu lớn.
Mục tiêu của tầng dưới là đảm bảo dữ liệu được đưa vào Data Warehouse một cách nhất quán, chính xác và sẵn sàng cho phân tích.
Tầng Giữa (Middle Tier): Công cụ phân tích
Chứa công cụ phân tích thường được vận hành bởi hệ thống OLAP (Xử lý phân tích trực tuyến). Khác với OLTP (chỉ xử lý giao dịch thời gian thực), OLAP sử dụng cấu trúc "khối" (cubes) để phân tích dữ liệu đa chiều tốc độ cao. Có 3 loại OLAP:
- MOLAP (Đa chiều): Xử lý nhanh nhất, làm việc trực tiếp với khối OLAP.
- ROLAP (Quan hệ): Phân tích trực tiếp trên các bảng quan hệ.
- HOLAP (Lai): Kết hợp sức mạnh của cơ sở dữ liệu quan hệ và đa chiều.
Tầng Trên (Top Tier): Giao diện người dùng
Tầng trên là lớp giao diện người dùng, nơi dữ liệu được hiển thị thông qua dashboard, báo cáo, biểu đồ hoặc công cụ BI. Người dùng kinh doanh có thể truy cập dữ liệu, tạo báo cáo, theo dõi xu hướng hoặc phát hiện bất thường mà không cần hiểu sâu về kỹ thuật dữ liệu.
Một số công cụ thường dùng ở tầng này gồm Tableau, Looker, Power BI, Qlik hoặc các hệ thống dashboard nội bộ.
Các thành phần chính trong kiến trúc Data Warehouse
Một Data Warehouse không chỉ là nơi lưu trữ dữ liệu, mà là hệ thống gồm nhiều thành phần phối hợp với nhau để thu thập, xử lý, quản trị và phân phối dữ liệu cho người dùng.
Công cụ ETL/ELT
Công cụ ETL/ELT chịu trách nhiệm trích xuất dữ liệu từ hệ thống nguồn, làm sạch, chuyển đổi và tải dữ liệu vào kho. Đây là thành phần quan trọng giúp dữ liệu trong Data Warehouse nhất quán và có thể sử dụng cho phân tích.
Ví dụ, dữ liệu ngày tháng từ nhiều hệ thống có thể có định dạng khác nhau. Công cụ ETL/ELT sẽ chuẩn hóa các định dạng này để khi đưa vào kho dữ liệu, người dùng có thể truy vấn chính xác.
Tầng API
Tầng API giúp Data Warehouse kết nối với các hệ thống vận hành, ứng dụng nội bộ, nền tảng phân tích hoặc công cụ trực quan hóa dữ liệu. Thông qua API, dữ liệu có thể được đồng bộ, chia sẻ hoặc truy cập linh hoạt hơn giữa các hệ thống.
Tầng dữ liệu trung tâm
Đây là phần lõi của Data Warehouse, nơi dữ liệu đã được tích hợp và lưu trữ. Tầng này có thể được vận hành bởi hệ quản trị cơ sở dữ liệu quan hệ, nền tảng Data Warehouse chuyên dụng hoặc dịch vụ kho dữ liệu trên cloud.
Tầng dữ liệu thường đi kèm các cơ chế bảo mật, phân quyền và quản trị dữ liệu để đảm bảo người dùng chỉ truy cập đúng phần dữ liệu họ được phép sử dụng.
Siêu dữ liệu (Metadata)
Metadata là dữ liệu mô tả dữ liệu. Nó cho biết dữ liệu đến từ đâu, được tạo khi nào, có cấu trúc ra sao, thuộc bảng nào, kiểu dữ liệu là gì và có thể dùng cho mục đích nào.
Metadata giúp việc tìm kiếm, quản lý, kiểm soát chất lượng và quản trị dữ liệu trở nên hiệu quả hơn. Với doanh nghiệp có lượng dữ liệu lớn, metadata là yếu tố quan trọng để tránh tình trạng dữ liệu khó tìm, khó hiểu hoặc bị sử dụng sai ngữ cảnh.
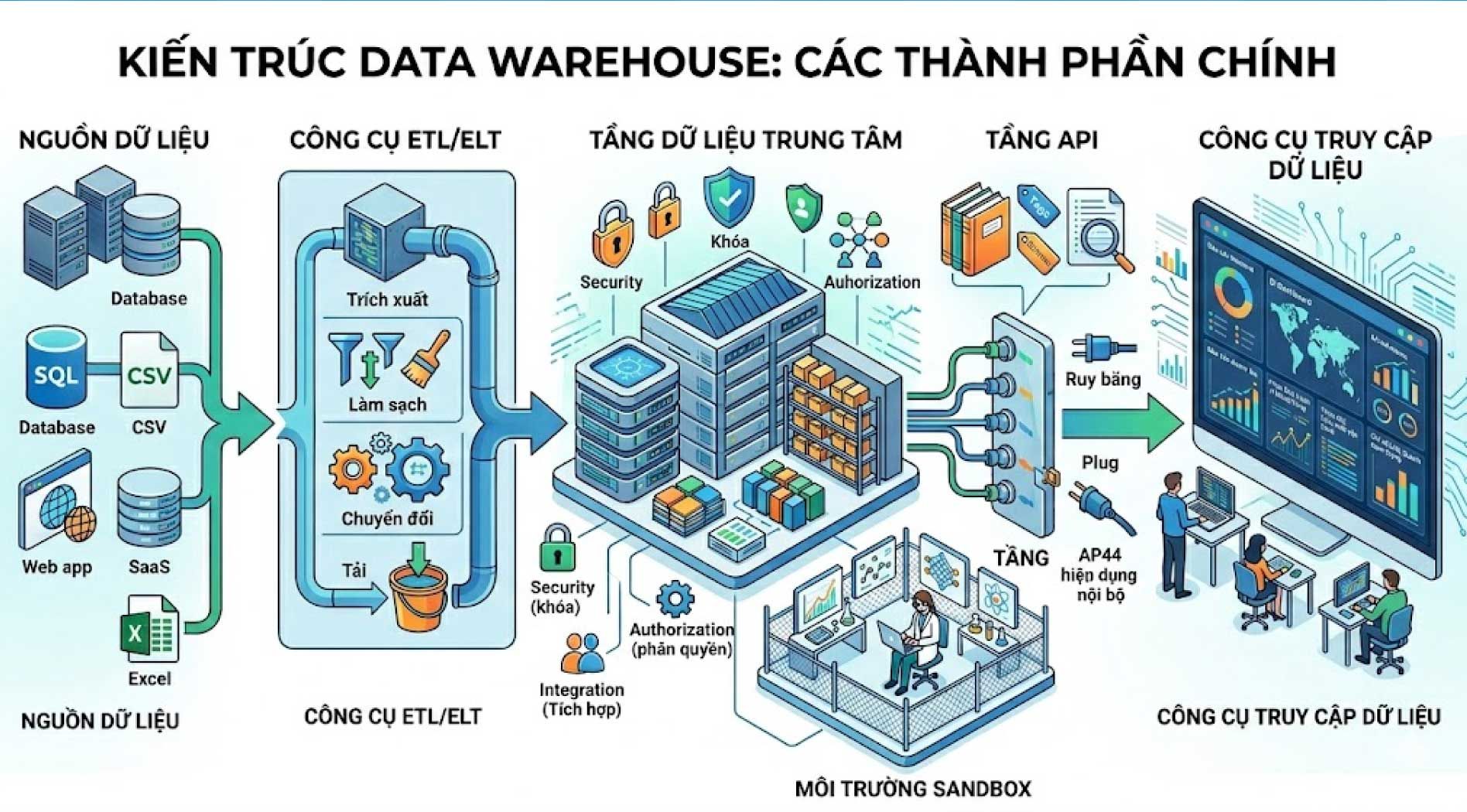
Sandbox
Sandbox là môi trường thử nghiệm tách biệt với hệ thống dữ liệu chính. Nhà phân tích dữ liệu hoặc data scientist có thể dùng sandbox để kiểm thử mô hình phân tích, thử nghiệm truy vấn, xây dựng thuật toán hoặc đánh giá phương pháp mới mà không ảnh hưởng đến dữ liệu sản xuất.
Công cụ truy cập dữ liệu (Access tools)
Công cụ truy cập dữ liệu là lớp front-end giúp người dùng tương tác với Data Warehouse. Các công cụ này có thể là dashboard, phần mềm BI, ứng dụng phân tích hoặc công cụ trực quan hóa dữ liệu.
Thông qua các công cụ này, người dùng có thể xem báo cáo doanh thu, phân tích hành vi khách hàng, theo dõi hiệu suất vận hành hoặc kiểm tra các chỉ số kinh doanh quan trọng.
Các Mô Hình Triển Khai Data Warehouse
Hiện nay, doanh nghiệp có thể lựa chọn 3 mô hình triển khai:
- Tại chỗ (On-premises): Hệ thống lưu trữ trên phần cứng nội bộ (kiến trúc MPP hoặc SMP). Đòi hỏi đầu tư lớn nhưng là lựa chọn bắt buộc cho các ngành có tiêu chuẩn bảo mật, quyền riêng tư cực kỳ khắt khe.
- Đám mây (Cloud): Cung cấp dưới dạng dịch vụ SaaS (Pay-as-you-go). Ưu điểm: Lưu trữ hàng Petabyte, dễ mở rộng, tiết kiệm chi phí hạ tầng và không cần quản lý phần cứng phức tạp.
- Lai (Hybrid): Kết hợp cả hai. Tận dụng sự linh hoạt của Cloud nhưng vẫn giữ các dữ liệu tối mật ở hệ thống máy chủ On-premises.
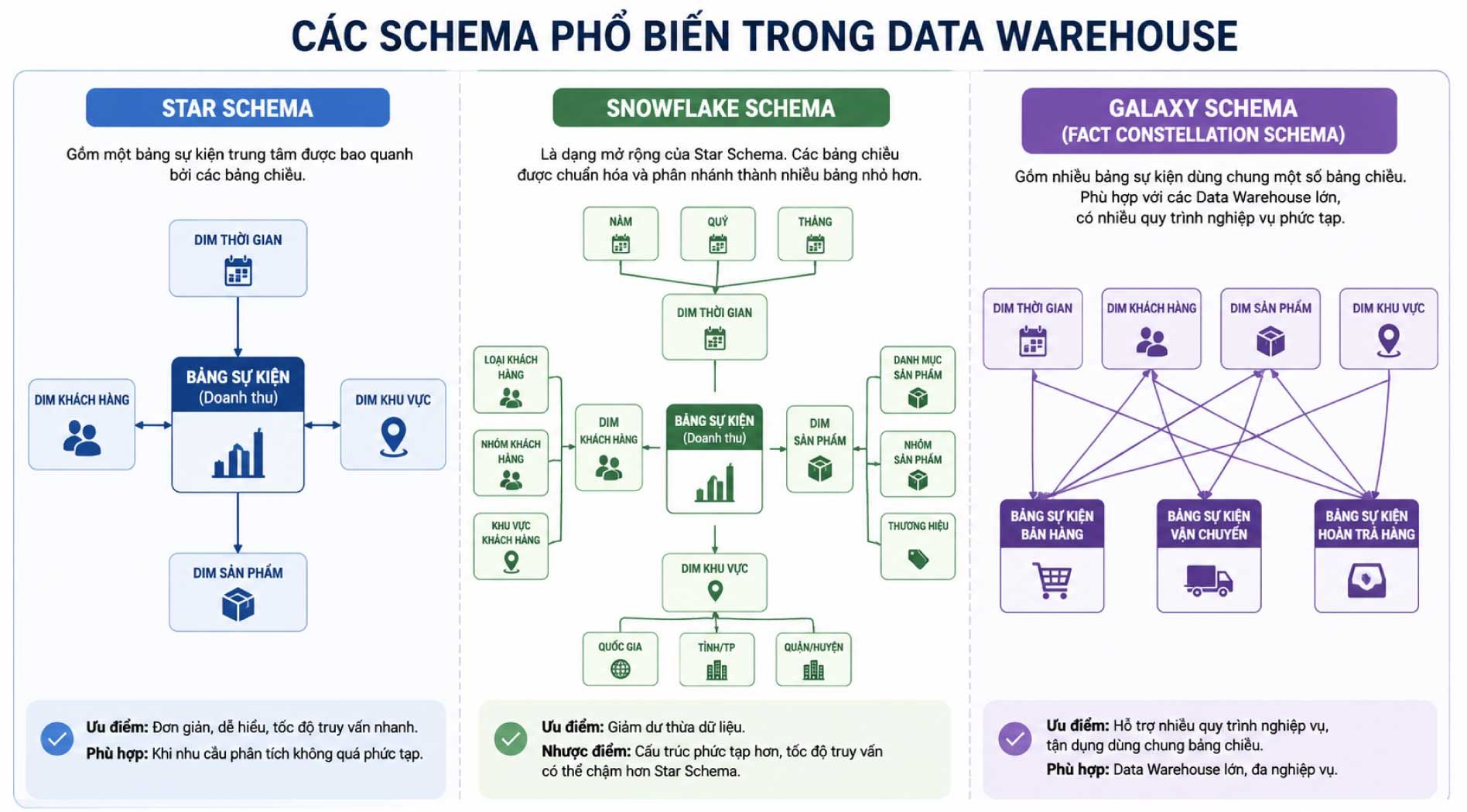
Các schema phổ biến trong Data Warehouse
Schema trong Data Warehouse là cách tổ chức dữ liệu để phục vụ truy vấn và phân tích. Schema trong Data Warehouse là cách tổ chức dữ liệu để phục vụ truy vấn và phân tích. Các schema thường sử dụng mô hình dữ liệu chiều, gồm bảng sự kiện và bảng chiều.
- Bảng sự kiện (Fact table): Lưu trữ dữ liệu định lượng như doanh thu, số lượng đơn hàng, chi phí, lợi nhuận hoặc lượt truy cập.
- Bảng chiều (Dimension table): Lưu trữ thông tin mô tả ngữ cảnh như thời gian, khu vực, sản phẩm, khách hàng hoặc kênh bán hàng.
Có 3 schema phổ biến trong Data Warehouse:
Star Schema
Star Schema, hay lược đồ hình sao, gồm một bảng sự kiện trung tâm được bao quanh bởi các bảng chiều. Đây là mô hình đơn giản, dễ hiểu và thường có tốc độ truy vấn nhanh.
Ví dụ, bảng doanh thu nằm ở trung tâm, xung quanh là các bảng chiều như thời gian, sản phẩm, khách hàng và khu vực. Khi cần phân tích doanh thu theo tháng hoặc theo khu vực, hệ thống có thể truy vấn nhanh từ các bảng này.
Snowflake Schema
Snowflake Schema, hay lược đồ bông tuyết, là dạng mở rộng của Star Schema. Trong mô hình này, các bảng chiều được chuẩn hóa và có thể phân nhánh thành nhiều bảng nhỏ hơn.
Ưu điểm của Snowflake Schema là giảm dư thừa dữ liệu. Tuy nhiên, do cấu trúc phức tạp hơn và cần nhiều phép nối bảng hơn, tốc độ truy vấn có thể chậm hơn so với Star Schema.
Galaxy Schema
Galaxy Schema, còn gọi là Fact Constellation Schema, gồm nhiều bảng sự kiện dùng chung một số bảng chiều. Mô hình này phù hợp với các Data Warehouse lớn, có nhiều quy trình nghiệp vụ phức tạp.
Ví dụ, một doanh nghiệp có thể có bảng sự kiện bán hàng, bảng sự kiện vận chuyển và bảng sự kiện hoàn trả hàng. Các bảng này có thể cùng dùng chung bảng chiều khách hàng, thời gian hoặc sản phẩm.
Phân loại Data Warehouse
Tùy theo quy mô sử dụng, Data Warehouse được chia thành 3 loại chính:
- Kho dữ liệu doanh nghiệp (EDW): Kho lưu trữ tập trung phục vụ toàn bộ doanh nghiệp, chứa dữ liệu lịch sử của mọi bộ phận.
- Kho dữ liệu hoạt động (ODS): Chứa "ảnh chụp nhanh" dữ liệu hoạt động cập nhật liên tục, phục vụ việc ra quyết định hàng ngày, gần thời gian thực.
- Siêu thị dữ liệu (Data Mart): Một tập con của kho dữ liệu, được thiết kế riêng biệt cho một phòng ban cụ thể (ví dụ: Data Mart riêng cho bộ phận Marketing) để tăng tốc độ trích xuất thông tin.
So sánh Data Warehouse, Database, Data Lake và Data Lakehouse
Data Warehouse, Database, Data Lake và Data Lakehouse đều liên quan đến lưu trữ dữ liệu, nhưng khác nhau về mục đích, loại dữ liệu và cách xử lý.
Tiêu chí | Database | Data Warehouse | Data Lake | Data Lakehouse |
| Bản chất | Cơ sở dữ liệu phục vụ ứng dụng cụ thể | Kho dữ liệu trung tâm phục vụ phân tích | Hồ dữ liệu lưu trữ dữ liệu thô quy mô lớn | Nền tảng kết hợp Data Lake và Data Warehouse |
| Mục đích chính | Xử lý giao dịch hằng ngày | Truy vấn, báo cáo, BI và phân tích lịch sử | Lưu trữ dữ liệu đa dạng với chi phí thấp | Phân tích dữ liệu lớn, AI/ML và BI trên cùng nền tảng |
| Cơ chế xử lý | OLTP | OLAP | Lưu trữ và xử lý dữ liệu thô | Kết hợp lưu trữ linh hoạt và phân tích hiệu năng cao |
| Loại dữ liệu | Chủ yếu dữ liệu có cấu trúc | Dữ liệu đã làm sạch, có cấu trúc | Có cấu trúc, bán cấu trúc, phi cấu trúc | Nhiều loại dữ liệu, gồm cả dữ liệu thời gian thực |
| Lược đồ | Schema-on-write | Schema-on-write | Schema-on-read | Linh hoạt, hỗ trợ quản trị và phân tích |
| Người dùng chính | Ứng dụng, lập trình viên, hệ thống vận hành | Nhà phân tích, BI, lãnh đạo doanh nghiệp | Data engineer, data scientist | BI, data science, AI/ML và phân tích dữ liệu lớn |
| Ví dụ sử dụng | Ghi nhận đơn hàng, thanh toán, tài khoản | Báo cáo doanh thu, phân tích khách hàng | Lưu log, video, dữ liệu IoT, dữ liệu mạng xã hội | Phân tích dữ liệu lớn, huấn luyện mô hình AI, báo cáo nâng cao |
Hiểu rõ Data Warehouse là gì và khác gì với Database, Data Lake, Data Lakehouse sẽ giúp doanh nghiệp xây dựng kiến trúc dữ liệu phù hợp hơn. Mỗi mô hình có vai trò riêng, nhưng Data Warehouse vẫn là nền tảng quan trọng cho báo cáo, BI và phân tích dữ liệu kinh doanh.








