VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



Distributed Tracing và vai trò của APM trong hệ sinh thái Observability hiện đại


Sự dịch chuyển từ kiến trúc monolithic sang microservices, cùng với sự phổ biến của container và nền tảng cloud, đã thúc đẩy mô hình cloud-native trở thành xu hướng chủ đạo trong phát triển ứng dụng hiện đại. Trong môi trường đó, hệ thống được triển khai động, phân tán và tự động mở rộng, khiến việc giám sát và phân tích hành vi ứng dụng trở nên phức tạp hơn đáng kể. Các phương pháp truyền thống như chỉ theo dõi log hoặc metrics không còn đủ để trả lời những câu hỏi quan trọng trong quá trình vận hành, chẳng hạn như:
- Vì sao ứng dụng bị chậm?
- Endpoint nào đang phát sinh lỗi?
- Lỗi nằm ở code, service trung gian hay database?
- Một giao dịch của người dùng đã đi qua những thành phần nào trong hệ thống?
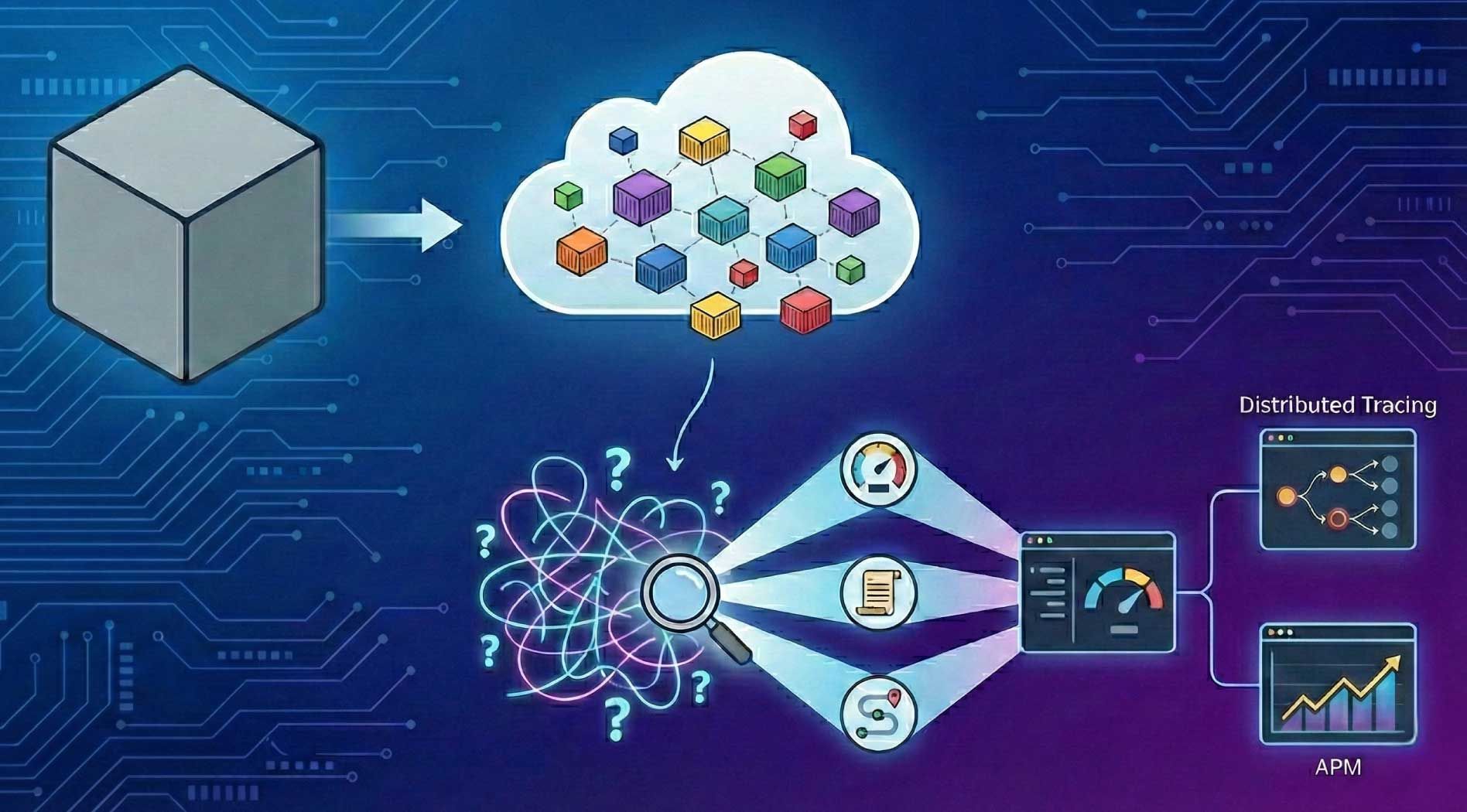
Để quan sát toàn trình một hệ thống phân tán, các đội kỹ thuật hiện đại xây dựng nền tảng Observability dựa trên ba loại tín hiệu cốt lõi: metrics, logs và traces. Trên nền tảng đó, Application Performance Monitoring (APM) đóng vai trò là lớp giám sát hiệu năng ứng dụng, trong khi Distributed Tracing là năng lực then chốt giúp theo dõi chi tiết hành trình end-to-end của từng request xuyên suốt các service. Sự kết hợp này cho phép không chỉ phát hiện sự cố kịp thời mà còn phân tích và xác định chính xác nguyên nhân gốc rễ của các vấn đề về hiệu năng và độ tin cậy của hệ thống.
APM trong Observability
Application Performance Monitoring (APM) là một thành phần quan trọng trong hệ sinh thái Observability, tập trung vào việc quan sát và đánh giá hiệu năng của ứng dụng thông qua các chỉ số định lượng (metrics) và ngữ cảnh giao dịch (transactions) theo thời gian thực.
Trong bức tranh Observability, APM đóng vai trò cầu nối giữa:
- Monitoring: cung cấp số liệu hiệu năng liên tục
- Logging: gắn lỗi và sự kiện với giao dịch cụ thể
- Tracing: (khi được tích hợp) mở rộng khả năng phân tích luồng xử lý
APM giúp trả lời câu hỏi cốt lõi: “Ứng dụng đang hoạt động tốt hay không, và mức độ ảnh hưởng đến người dùng là gì?”
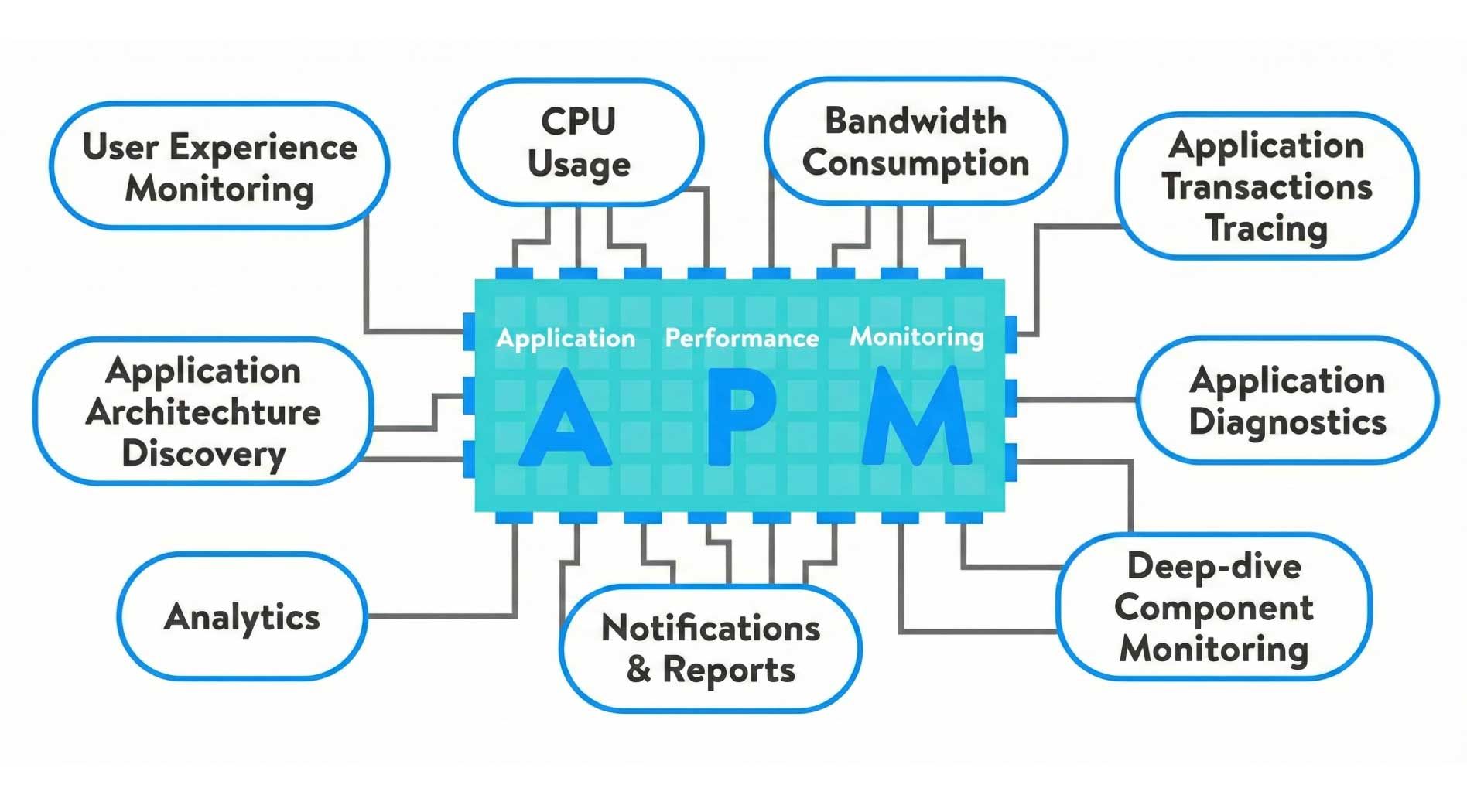
Các chỉ số hiệu năng then chốt của APM
- Thời gian phản hồi (Response Time / Latency): Đo lường thời gian xử lý của mỗi request hoặc giao dịch. Trong Observability, chỉ số này phản ánh trực tiếp trải nghiệm người dùng và thường được phân tích theo percentile (P95, P99) thay vì chỉ nhìn giá trị trung bình
- Tỷ lệ lỗi (Error Rate): Theo dõi số lượng và tần suất lỗi phát sinh trong quá trình xử lý request. APM giúp liên kết lỗi với endpoint, service hoặc giao dịch cụ thể, tạo nền tảng để phân tích sâu hơn bằng log hoặc trace khi cần.
- Throughput / TPS (Transactions Per Second): Phản ánh lưu lượng giao dịch mà ứng dụng đang xử lý. Khi kết hợp với latency và error rate, throughput giúp xác định vấn đề đến từ quá tải hay từ logic xử lý bên trong ứng dụng.
- Mức sử dụng tài nguyên Theo dõi CPU, RAM, thread, connection pool… của ứng dụng. Đây là lớp quan sát quan trọng để đánh giá mối tương quan giữa hiệu năng ứng dụng và tài nguyên hạ tầng trong toàn bộ hệ observability
- Các transaction quan trọng trong ứng dụng: APM cho phép định nghĩa và giám sát các transaction nghiệp vụ then chốt (ví dụ: đăng nhập, thanh toán, tạo đơn hàng). Mỗi transaction đại diện cho một luồng xử lý hoàn chỉnh từ góc nhìn người dùng hoặc nghiệp vụ. Điều này giúp Observability không chỉ dừng ở việc theo dõi hạ tầng, mà gắn trực tiếp hiệu năng hệ thống với giá trị và trải nghiệm kinh doanh.
Mục tiêu của APM
- Phát hiện sớm sự cố hiệu năng: APM cung cấp tín hiệu sớm khi hiệu năng bắt đầu suy giảm, ngay cả khi hệ thống chưa phát sinh lỗi nghiêm trọng.
- Xác định phạm vi và mức độ ảnh hưởng: Thông qua việc phân tích theo service, endpoint và giao dịch, APM giúp đánh giá nhanh phần nào của hệ thống và nhóm người dùng nào đang bị tác động.
- Đảm bảo trải nghiệm người dùng cuối: Trong Observability, APM đóng vai trò đại diện cho “góc nhìn người dùng”, đảm bảo các chỉ số kỹ thuật luôn gắn với trải nghiệm thực tế.
- Duy trì và cải thiện SLA/SLO: Dữ liệu từ APM là cơ sở để đo lường, đánh giá và tối ưu các cam kết SLA/SLO trong quá trình vận hành.
Ví dụ:
Khi trang đăng nhập của một ứng dụng web trở nên chậm, APM trong hệ observability sẽ cho thấy latency tăng bất thường ở giao dịch đăng nhập, đồng thời ghi nhận throughput giảm hoặc error rate tăng. Từ đây, đội kỹ thuật có thể tiếp tục sử dụng log và tracing để đi sâu phân tích nguyên nhân, nhưng APM chính là điểm khởi đầu giúp nhận diện vấn đề một cách nhanh và có ngữ cảnh.
Hiểu về Distributed Tracing
Distributed Tracing cho phép theo dõi hành trình end-to-end của một request khi nó đi qua nhiều service trong hệ thống phân tán. Thay vì chỉ quan sát các chỉ số tổng hợp, distributed tracing cung cấp dữ liệu chi tiết ở mức từng giao dịch, cho phép đội ngũ kỹ thuật phân tích chính xác cách request được xử lý trong toàn bộ hệ thống.
- Xác định rõ request đã đi qua những service nào, từ gateway, backend service đến database hoặc các hệ thống bên thứ ba.
- Đo lường thời gian xử lý tại từng service, từ đó nhanh chóng phát hiện service gây độ trễ bất thường.
- Khoanh vùng bottleneck hoặc điểm phát sinh lỗi một cách chính xác, thay vì phải phân tích thủ công log rời rạc.
- Làm rõ nguyên nhân giao dịch bị chậm, dù vấn đề xuất phát từ truy vấn database, cache miss hay API downstream phản hồi chậm.
Distributed tracing đặc biệt quan trọng trong kiến trúc microservices, nơi một request có thể đi qua hàng chục thành phần và các vấn đề hiệu năng thường khó xác định nếu chỉ dựa vào monitoring truyền thống.
Ví dụ:
Trong một hệ thống thương mại điện tử triển khai theo mô hình microservices, một giao dịch checkout thường phải đi qua nhiều bước: xác thực người dùng, kiểm tra giỏ hàng, tính giá, thanh toán và ghi nhận đơn hàng. Khi người dùng phản ánh rằng quá trình thanh toán diễn ra chậm, Distributed Tracing cho phép theo dõi toàn bộ hành trình của request checkout này:
- Request được gửi từ frontend đến API Gateway.
- Gateway chuyển tiếp request đến Order Service để xử lý đơn hàng.
- Order Service tiếp tục gọi Payment Service để thực hiện thanh toán.
- Payment Service gọi API của ngân hàng hoặc cổng thanh toán bên thứ ba.
- Sau khi thanh toán thành công, hệ thống ghi dữ liệu vào database.

Nhờ dữ liệu tracing, đội kỹ thuật có thể thấy rõ:
- Tổng thời gian xử lý của giao dịch là 2,5 giây.
- Riêng bước gọi API ngân hàng chiếm tới 1,8 giây, trong khi các service khác chỉ mất vài chục mili-giây.
Vai trò Distributed Tracing trong APM
APM không chỉ dừng lại ở việc thu thập các chỉ số hiệu năng tổng hợp (metrics) như độ trễ, tỷ lệ lỗi hay throughput. Trong các kiến trúc cloud-native và microservices, APM cần khả năng đi sâu vào từng giao dịch cụ thể để giải thích vì sao các chỉ số đó thay đổi. Đây chính là vai trò của tracing trong APM.
Distributed Tracing cung cấp lớp quan sát chi tiết ở mức từng request/transaction, cho phép APM theo dõi toàn bộ hành trình xử lý của một giao dịch từ điểm vào hệ thống (API Gateway, Ingress) cho đến các backend service, database, message queue và các API bên ngoài. Nhờ đó, APM không chỉ cho biết hệ thống đang chậm, mà còn chỉ ra chậm ở đâu và vì sao chậm.

Dưới đây là cách tracing mở rộng sức mạnh của APM:
Giám sát toàn trình
Distributed tracing theo dõi toàn bộ hành trình của một request từ điểm vào hệ thống (API Gateway, Ingress) cho đến các backend service, database, message queue và cả các API bên ngoài. Nhờ đó, đội ngũ vận hành có thể quan sát xuyên suốt toàn bộ luồng xử lý, thay vì chỉ thấy trạng thái rời rạc của từng service như khi sử dụng APM đơn thuần.
Xác định bottleneck chính xác
Thông qua dữ liệu tracing, APM có thể nhanh chóng xác định điểm nghẽn trong luồng giao dịch, ví dụ:
- Truy vấn SQL thực thi chậm
- Một microservice phản hồi lỗi hoặc có độ trễ cao
- API downstream bị timeout
- Message queue bị tồn đọng backlog
Rút ngắn thời gian xử lý sự cố (MTTR)
Tracing giúp đội kỹ thuật khoanh vùng chính xác request gặp lỗi và thành phần gây ra sự cố chỉ trong vài phút, thay vì phải dò tìm thủ công qua nhiều hệ thống log khác nhau. Điều này làm giảm đáng kể MTTR và hạn chế ảnh hưởng tới người dùng.Thay vì dò log thủ công, tracing cho biết request nào lỗi và lỗi ở đâu chỉ trong vài giây.
Tối ưu hiệu năng dựa trên dữ liệu
Bằng cách phân tích trace, APM cho thấy rõ service nào đang tiêu tốn nhiều thời gian nhất, code path nào chưa tối ưu, hoặc độ trễ phát sinh từ network hay phụ thuộc bên ngoài. Việc tối ưu được thực hiện dựa trên dữ liệu thực, không dựa trên phỏng đoán
Tăng chiều sâu cho hệ quan sát
Khi kết hợp tracing với metrics và logging trong APM, hệ thống quan sát đạt được cái nhìn toàn diện:
- Metrics cho biết điều gì đang xảy ra
- Tracing cho biết vì sao xảy ra
- Logs cung cấp bằng chứng chi tiết để xác nhận nguyên nhân
Thiết kế cho microservices
Trong môi trường microservices, nơi một transaction có thể đi qua hàng chục service, tracing là năng lực gần như bắt buộc để APM có thể phản ánh đúng hành vi hệ thống và hỗ trợ vận hành hiệu quả.
Bắt đầu với APM và Distributed Tracing
Hiện nay có rất nhiều công cụ và giải pháp giám sát, phân tích log và tracing như Jaeger, Tempo, Datadog …Tuy nhiên, khi triển khai rời rạc các công cụ cho metrics, logs và traces, dữ liệu thường bị phân mảnh, gây khó khăn cho việc phân tích sự cố và xây dựng góc nhìn thống nhất. Thách thức này càng rõ rệt trong các môi trường triển khai hỗn hợp giữa cloud và on-premises, nơi việc tích hợp, vận hành và quản lý hệ thống giám sát trở nên phức tạp hơn.
Vì vậy, xu hướng hiện nay là sử dụng nền tảng Observability tích hợp, nơi APM kết hợp cùng Tracing, Metrics và Logging được hợp nhất trong một giao diện thống nhất. Cách tiếp cận này cho phép liên kết dữ liệu theo cùng ngữ cảnh (transaction, service, request), từ đó rút ngắn thời gian phân tích và nâng cao hiệu quả vận hành.
Với vai trò là một hệ sinh thái đám mây hoàn chỉnh từ IaaS đến PaaS, VNPT Cloud cung cấp sẵn dịch vụ VNPT APM, cho phép tích hợp giám sát hiệu năng ứng dụng trực tiếp trên hạ tầng cloud. Giải pháp được thiết kế theo mô hình self-service, giúp đội ngũ kỹ thuật triển khai nhanh, cấu hình đơn giản và dễ dàng mở rộng theo nhu cầu vận hành thực tế.