VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



Self Healing trong Kubernetes là gì? Cơ chế tự phục hồi của K8s


Trong môi trường Kubernetes, sự cố như container crash, Pod bị xóa hoặc node mất kết nối có thể xảy ra bất cứ lúc nào. Self Healing trong Kubernetes giúp hệ thống tự phát hiện lỗi và thực hiện hành động phục hồi cần thiết để duy trì trạng thái mong muốn của workload. Bài viết này sẽ giúp bạn hiểu Self Healing là gì, cách hoạt động và những lưu ý khi áp dụng trong môi trường production.
Kubernetes Self Healing là gì?
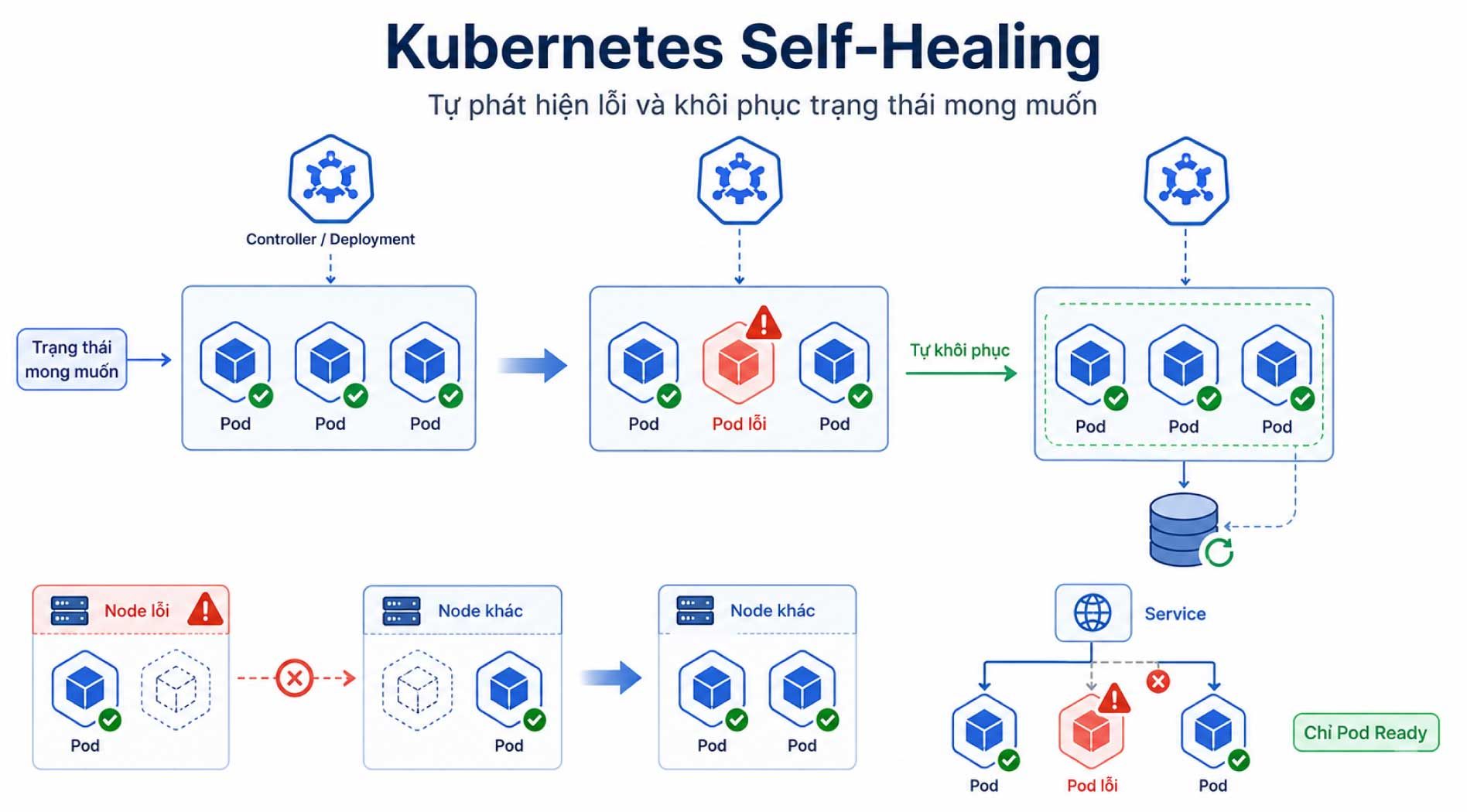
Self Healing trong Kubernetes là khả năng tự động phát hiện một số sự cố của workload và thực hiện các hành động cần thiết để duy trì trạng thái đã được khai báo.
Ứng dụng trên Kubernetes thường được triển khai và quản lý thông qua các controller như Deployment, StatefulSet hoặc DaemonSet thay vì chạy dưới dạng một Pod đơn lẻ. Ví dụ, một Deployment được khai báo cần chạy 3 Pod. Nếu một Pod bị lỗi hoặc bị xóa, Kubernetes sẽ phát hiện trạng thái thực tế chỉ còn 2 Pod và tạo Pod mới để đưa hệ thống trở lại 3 Pod như cấu hình ban đầu.
Nói đơn giản, Self Healing giúp Kubernetes trả lời câu hỏi:
“Trạng thái hiện tại của hệ thống có đúng với trạng thái mong muốn không? Nếu không đúng, cần làm gì để đưa hệ thống trở lại đúng trạng thái?”
Khả năng tự phục hồi trong Kubernetes bao gồm:
- Restart container khi ứng dụng gặp sự cố hoặc thoát bất thường.
- Tạo Pod thay thế khi Pod hiện tại không còn hoạt động.
- Tái tạo workload trên node khác khi node gặp sự cố hoặc không còn khả dụng.
- Khôi phục quyền truy cập Persistent Volume khi workload được tạo lại trong một số trường hợp.
- Loại các Pod chưa sẵn sàng nhận traffic khỏi endpoint của Service.
Vì vậy, Self Healing trong Kubernetes không chỉ là “tự restart container”, mà là tập hợp nhiều cơ chế phối hợp giữa kubelet, controller, scheduler, Service và storage controller để duy trì workload ổn định hơn.
Vì sao Kubernetes cần khả năng tự phục hồi?
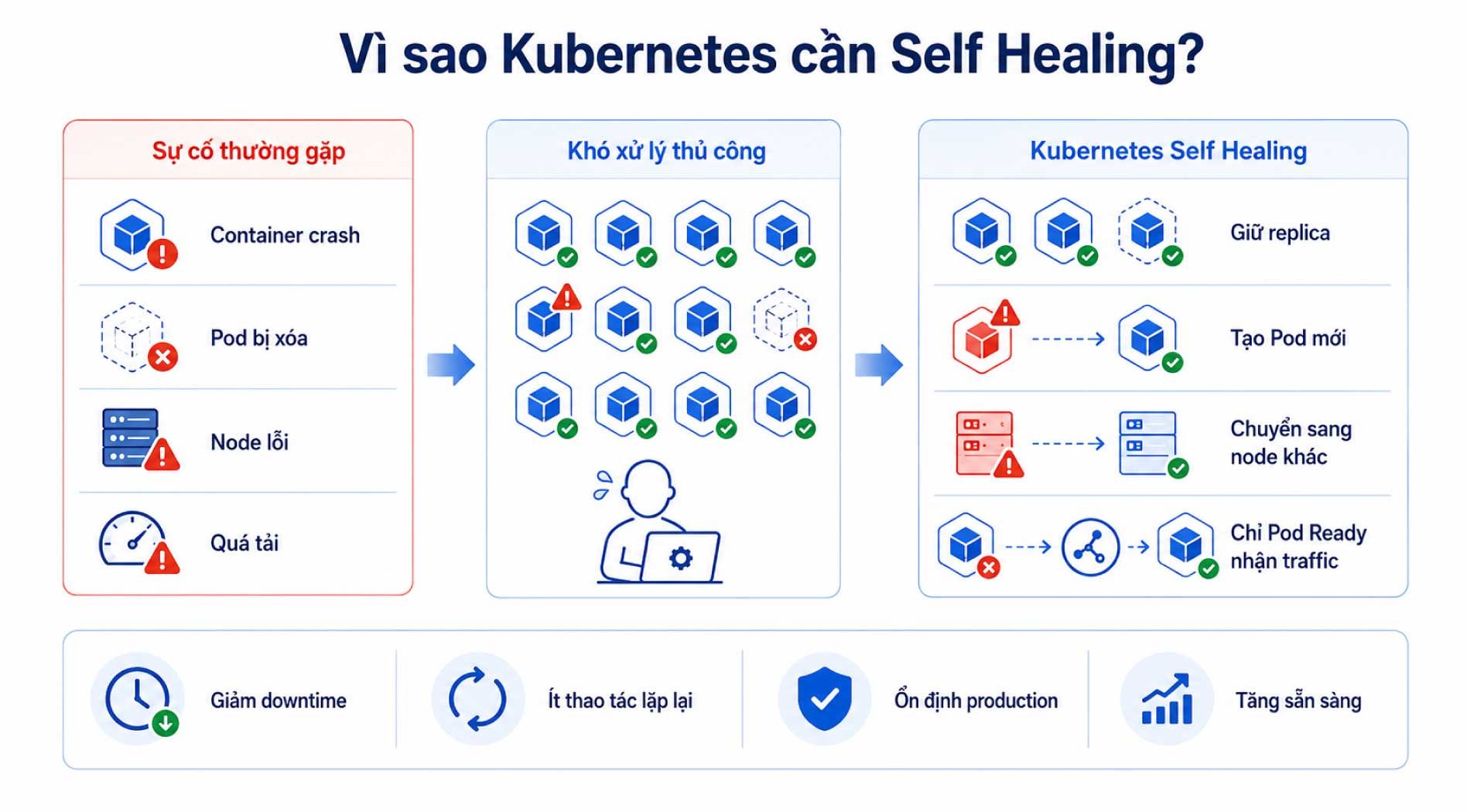
Trong môi trường container và cloud-native, lỗi là điều khó tránh khỏi. Container có thể crash, ứng dụng có thể treo, Pod có thể bị xóa, node có thể mất kết nối hoặc tài nguyên hệ thống có thể bị quá tải.
Nếu mọi sự cố đều cần kỹ sư vận hành đăng nhập vào máy chủ để kiểm tra và restart thủ công, hệ thống sẽ khó đáp ứng yêu cầu production. Đặc biệt với microservices, một ứng dụng có thể bao gồm hàng chục hoặc hàng trăm service nhỏ. Việc khôi phục thủ công từng thành phần sẽ mất thời gian, dễ sai sót và làm tăng downtime.
Self Healing giúp Kubernetes giải quyết vấn đề này bằng cách tự động hóa một phần quá trình phục hồi. Khi trạng thái thực tế lệch khỏi trạng thái mong muốn, Kubernetes có thể chủ động thực hiện hành động cần thiết thay vì chờ con người can thiệp.
Khả năng tự phục hồi đặc biệt quan trọng trong các trường hợp:
- Ứng dụng cần duy trì số lượng replica ổn định.
- Hệ thống có nhiều Pod phân tán trên nhiều node.
- Doanh nghiệp cần giảm thời gian gián đoạn dịch vụ.
- Ứng dụng cần tự động loại bỏ instance lỗi khỏi luồng traffic.
- Đội ngũ DevOps muốn giảm thao tác vận hành lặp lại.
- Hệ thống production cần duy trì tính sẵn sàng cao hơn.
Tuy nhiên, Self Healing chỉ là một lớp trong chiến lược vận hành Kubernetes. Nó giúp khôi phục workload ở một số tình huống phổ biến, nhưng không thay thế được observability, backup dữ liệu hoặc kiến trúc High Availability.
Cách hoạt động của Self Healing trong Kubernetes
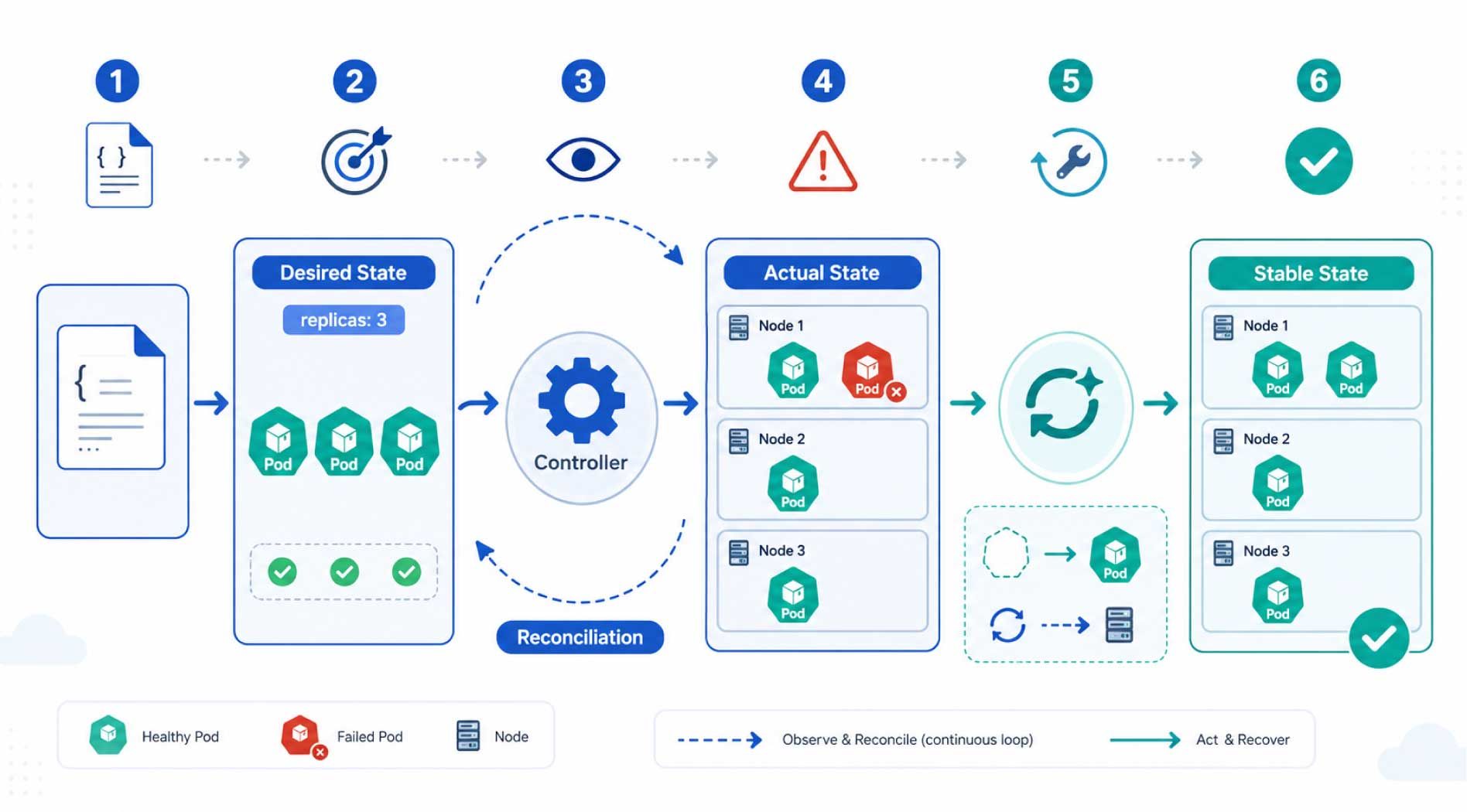
Cơ chế Self Healing trong Kubernetes dựa trên nguyên tắc cốt lõi: so sánh liên tục giữa desired state và actual state.
Trong đó:
- Desired state là trạng thái mong muốn do người dùng khai báo.
- Actual state là trạng thái thực tế đang diễn ra trong cluster.
- Controller là thành phần theo dõi sự khác biệt giữa hai trạng thái này.
- Khi phát hiện sai lệch, Kubernetes thực hiện hành động để đưa actual state về gần desired state nhất có thể.
Quy trình có thể hiểu theo các bước sau:
- Bước 1: Người quản trị khai báo cấu hình workload
Ví dụ, bạn tạo một Deployment với replicas: 3, nghĩa là hệ thống cần luôn duy trì 3 Pod cho ứng dụng đó. - Bước 2: Kubernetes lưu trạng thái mong muốn
Cấu hình này được gửi đến API Server và trở thành trạng thái mong muốn của cluster. - Bước 3: Controller quan sát trạng thái thực tế
Các controller trong Kubernetes liên tục theo dõi xem số lượng Pod thực tế, trạng thái Pod, node và các object liên quan có khớp với cấu hình mong muốn hay không. - Bước 4: Kubernetes phát hiện sai lệch
Nếu một Pod bị xóa, container bị lỗi hoặc node không khả dụng, trạng thái thực tế sẽ không còn đúng với trạng thái mong muốn. - Bước 5: Kubernetes thực hiện hành động phục hồi
Tùy tình huống, Kubernetes có thể restart container, tạo Pod thay thế, điều phối Pod sang node khác hoặc loại Pod lỗi khỏi Service endpoint. - Bước 6: Hệ thống quay lại trạng thái ổn định hơn
Sau khi hành động phục hồi hoàn tất, workload tiếp tục vận hành theo cấu hình đã khai báo.
Điểm quan trọng là Kubernetes vận hành theo mô hình reconciliation loop. Nghĩa là hệ thống không chỉ kiểm tra một lần, mà liên tục quan sát và điều chỉnh để trạng thái thực tế tiến gần trạng thái mong muốn.
Ví dụ thực tế về Self Healing trong Kubernetes
Giả sử bạn triển khai một ứng dụng backend bằng Deployment với 3 replicas:
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-api
spec:
replicas: 3
selector:
matchLabels:
app: backend-api
template:
metadata:
labels:
app: backend-api
spec:
containers:
- name: backend-api
image: example/backend-api:v1
ports:
- containerPort: 8080Khi Deployment này được tạo, Kubernetes sẽ cố gắng duy trì 3 Pod chạy ứng dụng backend-api.
Trường hợp 1: Một Pod bị xóa thủ công
Nếu người vận hành chạy lệnh xóa một Pod:
kubectl delete pod backend-api-xxxxxKubernetes sẽ phát hiện Deployment chỉ còn 2 Pod thay vì 3 Pod như khai báo. ReplicaSet sẽ tạo Pod mới để đưa số lượng Pod trở lại 3.
Trường hợp 2: Container trong Pod bị crash
Nếu process chính trong container bị lỗi và container dừng, kubelet có thể restart container dựa trên restartPolicy. Đây là phục hồi ở cấp container.
Trường hợp 3: Node chạy Pod bị lỗi
Nếu node chứa một hoặc nhiều Pod của ứng dụng bị mất kết nối hoặc không khả dụng, Kubernetes có thể tạo Pod thay thế trên node khác, miễn là workload được quản lý bởi controller và cluster còn đủ tài nguyên.
Trường hợp 4: Pod chưa sẵn sàng nhận traffic
Nếu readiness probe thất bại, Pod có thể vẫn tồn tại nhưng không được Service gửi traffic đến. Điều này giúp tránh việc request đi vào Pod chưa sẵn sàng.
Qua các ví dụ trên, có thể thấy Self Healing trong K8s không chỉ là một hành động đơn lẻ. Nó là chuỗi phản ứng tự động ở nhiều tầng: container, Pod, node, replica và traffic routing.
Phân biệt Self Healing, High Availability và Autoscaling
Self Healing, High Availability và Autoscaling đều liên quan đến độ ổn định hệ thống, nhưng không giống nhau.
| Tiêu chí | Self Healing | High Availability | Autoscaling |
| Mục tiêu | Tự phục hồi khi workload gặp lỗi | Duy trì dịch vụ sẵn sàng cao | Tự tăng/giảm tài nguyên theo tải |
| Trọng tâm | Container, Pod, node, endpoint | Kiến trúc tổng thể | CPU, memory, request, custom metrics |
| Cơ chế phổ biến | restartPolicy, controller, probe, Service endpoint | multi-node, multi-zone, load balancing, replication | HPA, VPA, Cluster Autoscaler |
| Xử lý lỗi? | Có, ở một số tầng | Có, nhờ thiết kế dự phòng | Không trực tiếp, chủ yếu xử lý tải |
| Có thay thế nhau không? | Không | Không | Không |
Có thể hiểu đơn giản:
- Self Healing giúp hệ thống tự phục hồi khi có thành phần lỗi.
- High Availability giúp dịch vụ vẫn sẵn sàng khi có lỗi xảy ra.
- Autoscaling giúp hệ thống thích ứng với thay đổi về tải.
Trong production, ba cơ chế này nên được kết hợp với nhau thay vì xem là lựa chọn thay thế.
Cách cấu hình Self Healing trong Kubernetes hiệu quả
Để Self Healing hoạt động hiệu quả, doanh nghiệp không nên chỉ dựa vào cấu hình mặc định. Cần thiết kế workload và health check phù hợp ngay từ đầu.
Triển khai workload thông qua các controller thay vì tạo Pod độc lập.
Để Self-Healing hoạt động hiệu quả, workload nên được triển khai thông qua các controller như Deployment, StatefulSet hoặc DaemonSet thay vì tạo Pod trực tiếp.
Các controller này liên tục theo dõi trạng thái của workload và tự động thực hiện các hành động khôi phục khi phát hiện sai lệch so với cấu hình đã khai báo. Ví dụ, khi một Pod gặp sự cố, bị xóa hoặc node không còn khả dụng, controller sẽ tạo Pod thay thế để duy trì trạng thái mong muốn của ứng dụng.
Ngược lại, nếu chỉ tạo một Pod độc lập, Kubernetes sẽ không tự động tạo lại Pod khi Pod đó bị mất.
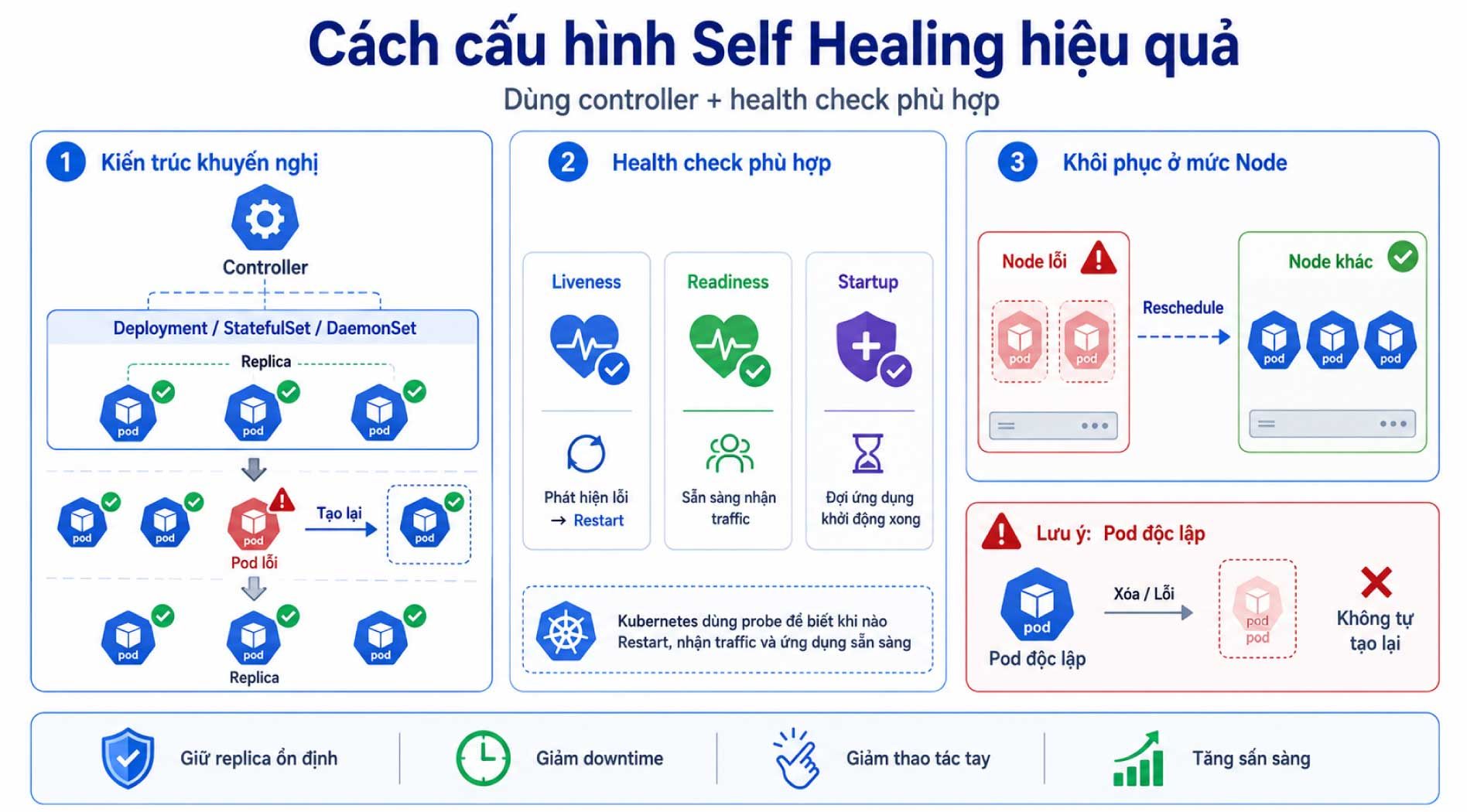
Cấu hình số replica phù hợp
Không nên chạy ứng dụng production quan trọng với chỉ 1 replica. Tối thiểu nên có nhiều replica để khi một Pod bị lỗi, các Pod còn lại vẫn có thể phục vụ traffic.
Ví dụ:
spec:
replicas: 3Số lượng replica cần dựa trên tải thực tế, yêu cầu SLA, tài nguyên cluster và thiết kế ứng dụng.
Tách liveness và readiness endpoint
Liveness và readiness không nên luôn dùng chung một endpoint.
- Liveness nên kiểm tra ứng dụng có cần restart hay không.
- Readiness nên kiểm tra ứng dụng có sẵn sàng nhận traffic hay không.
Ví dụ, nếu database tạm thời mất kết nối, chưa chắc ứng dụng cần restart. Trong nhiều trường hợp, readiness fail là đủ để tạm thời loại Pod khỏi traffic.
Dùng startup probe cho ứng dụng khởi động chậm
Nếu ứng dụng Java, .NET, AI service hoặc service cần warm up lâu, startup probe rất hữu ích. Nó giúp tránh tình trạng liveness probe restart container trước khi ứng dụng kịp khởi động hoàn chỉnh.
Thiết lập timeout và failureThreshold hợp lý
Không nên cấu hình probe quá gắt. Các tham số như initialDelaySeconds, periodSeconds, timeoutSeconds, failureThreshold cần dựa trên thời gian phản hồi thực tế của ứng dụng.
Nếu endpoint health check đôi khi chậm do tải cao, timeout quá thấp có thể gây restart không cần thiết.
Lưu ý khi vận hành Self Healing trong Production
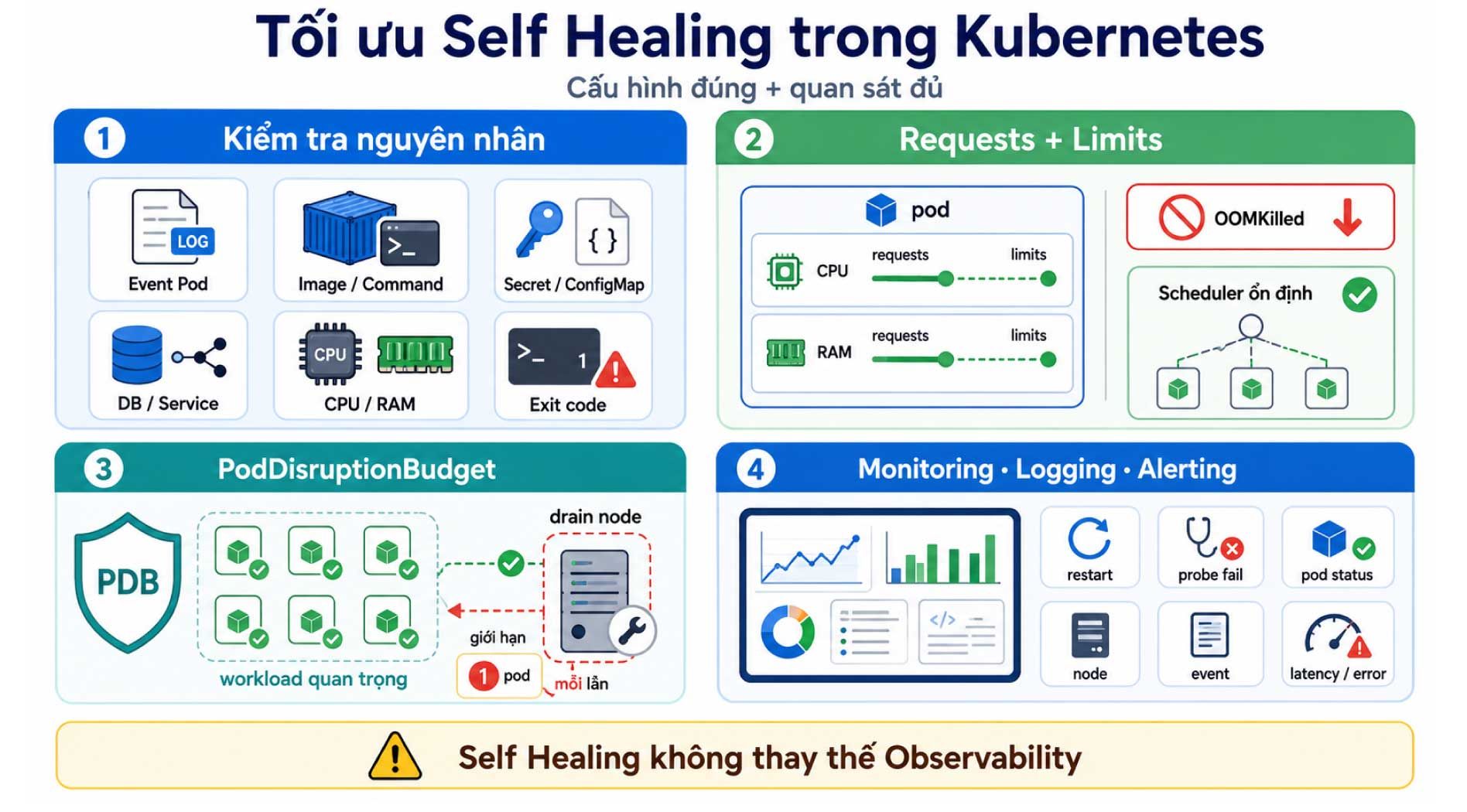
Theo dõi CrashLoopBackOff
CrashLoopBackOff là dấu hiệu quan trọng cho thấy container bị restart lặp lại. Khi gặp trạng thái này, không nên chỉ tăng timeout hoặc xóa Pod. Cần kiểm tra:
- Log ứng dụng.
- Event của Pod.
- Image và command khởi động.
- Secret/ConfigMap.
- Kết nối database hoặc service phụ thuộc.
- Resource limit CPU/RAM.
- Exit code của container.
Kết hợp resource requests và limits
Nếu không cấu hình resource requests/limits, scheduler khó đưa ra quyết định tối ưu và container có thể bị ảnh hưởng bởi thiếu tài nguyên. Với workload production, nên khai báo CPU và memory phù hợp để giảm rủi ro OOMKilled hoặc scheduling không ổn định.
Dùng PodDisruptionBudget cho workload quan trọng
PodDisruptionBudget giúp giới hạn số Pod có thể bị gián đoạn tự nguyện cùng lúc, ví dụ khi drain node hoặc bảo trì cluster. Đây không phải cơ chế Self Healing trực tiếp, nhưng giúp duy trì tính sẵn sàng khi cluster thay đổi.
Kết hợp monitoring, logging và alerting
Self Healing không thay thế observability. Hệ thống vẫn cần Prometheus, Grafana, Loki, EFK/ELK, OpenTelemetry hoặc công cụ tương đương để theo dõi:
- Số lần restart.
- Tỷ lệ probe failure.
- Pod pending/running/failed.
- Node condition.
- Event trong namespace.
- Latency và error rate của ứng dụng.
Nếu Kubernetes restart container nhiều lần nhưng không có cảnh báo, đội vận hành có thể bỏ lỡ lỗi nghiêm trọng.
Self Healing trong K8s là khả năng tự phục hồi quan trọng giúp Kubernetes duy trì trạng thái mong muốn của workload. Thông qua kubelet, restartPolicy, Deployment, ReplicaSet, StatefulSet, Service endpoint và các loại probe, Kubernetes có thể restart container, tạo Pod thay thế, điều phối workload khi node lỗi và hạn chế traffic đi vào Pod không khỏe.
Tuy nhiên, khả năng tự phục hồi trong Kubernetes không phải giải pháp thay thế cho thiết kế ứng dụng tốt, monitoring, backup hay High Availability. Để Self Healing phát huy hiệu quả trong môi trường production, đội ngũ vận hành cần cấu hình đúng probe, dùng controller phù hợp, triển khai nhiều replica, theo dõi log/metric và chuẩn bị phương án phục hồi dữ liệu khi có sự cố nghiêm trọng.