VNPT Cloud GPU
VNPT Cloud Backup
VNPT Cloud Box



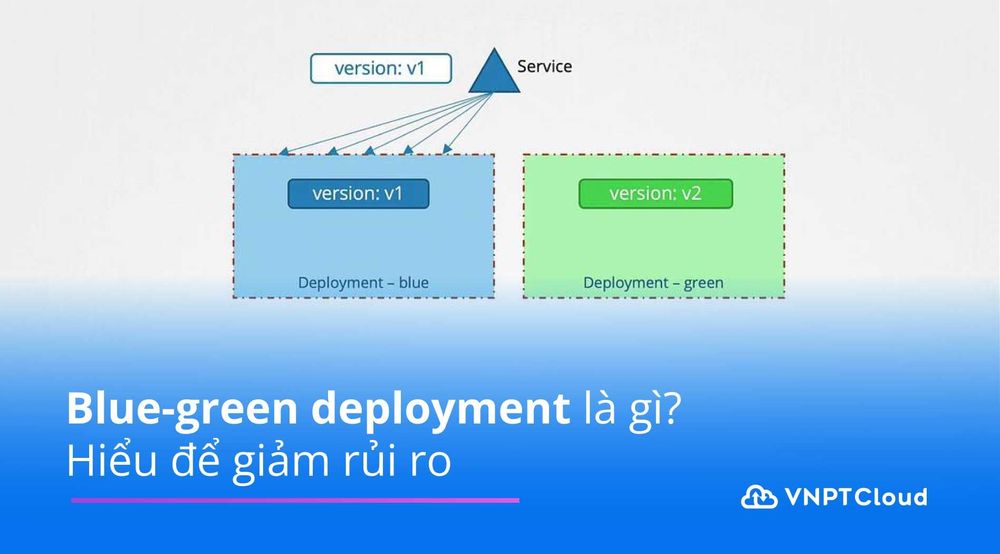
Site Reliability Engineering là gì? Cách SRE nâng cao độ tin cậy


Khi hệ thống ngày càng phức tạp, doanh nghiệp không chỉ cần phát triển tính năng nhanh mà còn phải duy trì dịch vụ ổn định và liên tục. Đây cũng là lý do nhiều người bắt đầu quan tâm đến Site Reliability Engineering như một hướng tiếp cận để cân bằng giữa tốc độ đổi mới và khả năng vận hành bền vững. Vậy Site Reliability Engineering là gì, cùng tìm hiểu qua bài viết dưới đây.
Site Reliability Engineering là gì?
Site Reliability Engineering (SRE) là một phương pháp kỹ thuật phần mềm kết hợp giữa DevOps và vận hành IT truyền thống nhằm giải quyết các vấn đề của khách hàng, tự động hóa các tác vụ vận hành, đẩy nhanh tốc độ bàn giao phần mềm và giảm thiểu rủi ro hệ thống.
Thuật ngữ “site reliability engineering” được Ben Sloss, Phó Chủ tịch Kỹ thuật của Google, đặt ra vào năm 2003. Ông là người nổi tiếng với câu mô tả trên hồ sơ LinkedIn rằng: “If Google ever stops working, it’s my fault”. Có thể hiểu là: “Nếu Google ngừng hoạt động, đó là lỗi của tôi.” Theo Google, SRE là cách tiếp cận xem vận hành như một bài toán phần mềm để giải quyết bằng tư duy kỹ thuật.
Dù mỗi tổ chức và mỗi hệ thống phần mềm đều có những đặc điểm riêng, việc hiểu rõ các nền tảng cốt lõi của SRE, cùng kỹ năng và tư duy của những kỹ sư làm trong lĩnh vực này, vẫn rất cần thiết. Điều đó giúp doanh nghiệp tối ưu độ tin cậy và nâng cao chất lượng tổng thể của hệ thống phần mềm.
Tại sao kỹ thuật SRE lại quan trọng?
Site Reliability Engineering (SRE) giúp doanh nghiệp duy trì độ ổn định của hệ thống, giảm rủi ro gián đoạn dịch vụ và nâng cao chất lượng vận hành. Đây là cách tiếp cận quan trọng để cân bằng giữa tốc độ phát triển và độ tin cậy của ứng dụng.
Cải thiện khả năng phối hợp
Site Reliability Engineering (SRE) đóng vai trò quan trọng trong việc duy trì độ ổn định và chất lượng dịch vụ của ứng dụng sau khi đưa vào vận hành. Khi hệ thống liên tục được cập nhật và mở rộng, nguy cơ phát sinh lỗi hoặc gián đoạn là điều khó tránh khỏi. SRE giúp doanh nghiệp kiểm soát rủi ro này tốt hơn, đồng thời nâng cao hiệu quả phối hợp, trải nghiệm người dùng và khả năng lập kế hoạch vận hành.
Nâng cao trải nghiệm khách hàng
Một trong những mục tiêu quan trọng của SRE là giảm thiểu tác động của lỗi phần mềm đến người dùng cuối. Bằng cách áp dụng tự động hóa trong vòng đời phát triển phần mềm, đội ngũ kỹ thuật có thể hạn chế sai sót và duy trì chất lượng dịch vụ ổn định hơn. Điều này giúp khách hàng có trải nghiệm mượt mà hơn, đồng thời cho phép doanh nghiệp tập trung nhiều hơn vào đổi mới tính năng.
Cải thiện việc lập kế hoạch vận hành
SRE không xem sự cố là điều bất thường, mà coi đó là khả năng luôn có thể xảy ra trong thực tế. Vì vậy, các nhóm SRE thường chủ động chuẩn bị kịch bản phản ứng sự cố để giảm thiểu ảnh hưởng của downtime đến người dùng và hoạt động kinh doanh. Cách tiếp cận này cũng giúp doanh nghiệp đánh giá tốt hơn chi phí gián đoạn và xây dựng kế hoạch vận hành thực tế hơn.

Các chỉ số đo lường trong SRE
Các kỹ sư SRE sử dụng nhiều chỉ số khác nhau để theo dõi tính nhất quán của việc cung cấp dịch vụ và độ tin cậy của hệ thống phần mềm, bao gồm:
Thỏa thuận mức độ dịch vụ (SLA - Service Level Agreement)
SLA thiết lập các điều khoản và điều kiện giữa nhà cung cấp dịch vụ và khách hàng. Các thỏa thuận này quy định mức độ hiệu suất, các chỉ số đã thống nhất để đo lường hiệu suất và các hậu quả nếu không đạt được cam kết. Một dịch vụ phổ biến thường được nêu trong SLA là uptime (thời gian hoạt động), hoặc khoảng thời gian dịch vụ sẵn sàng phục vụ.
Ngân sách lỗi (Error Budgets)
Ngân sách lỗi là một công cụ mà các đội ngũ SRE sử dụng để điều hòa một cách tự động giữa độ tin cậy dịch vụ và tốc độ phát triển, đổi mới phần mềm của công ty. Ngân sách lỗi thiết lập một mức độ rủi ro sai sót phù hợp với các thỏa thuận mức độ dịch vụ (SLA).
Ví dụ, mục tiêu thời gian hoạt động là 99,999% (được gọi là tiêu chuẩn "năm số chín") là một ngưỡng SLA phổ biến. Điều này có nghĩa là ngân sách lỗi hàng tháng - tổng thời gian ngừng hoạt động tối đa cho phép mà không vi phạm hợp đồng trong một tháng khoảng 4 phút 23 giây. Nếu đội ngũ phát triển muốn triển khai các tính năng hoặc cải tiến mới, hệ thống phải đảm bảo không được vượt quá ngân sách lỗi này.
Ngân sách lỗi giúp đội ngũ phát triển và vận hành cải thiện tính ổn định và hiệu suất dịch vụ. Chúng cũng giúp đưa ra các quyết định dựa trên dữ liệu về việc triển khai tính năng mới và tối đa hóa khả năng đổi mới bằng cách chấp nhận rủi ro trong giới hạn cho phép.
Mục tiêu mức độ dịch vụ (SLO - Service Level Objective)
Các đội ngũ SRE cũng giúp thiết lập các mục tiêu mức độ dịch vụ (SLO). Đây là một mục tiêu hiệu suất đã được thống nhất cho một dịch vụ cụ thể trong một khoảng thời gian xác định. SLO định nghĩa trạng thái mong đợi của dịch vụ, giúp các bên liên quan quản lý "sức khỏe" của từng dịch vụ cụ thể và đáp ứng các cam kết trong SLA.
Chỉ số mức độ dịch vụ (SLI - Service Level Indicator)
SLO được đo lường bằng các chỉ số mức độ dịch vụ (SLI). SLI là các phép đo định lượng được trình bày dưới dạng phần trăm, trung bình hoặc tỷ lệ. Chúng bao gồm các phép đo thực tế của dịch vụ như:
- Uptime: Thời gian hoạt động.
- Latency: Độ trễ.
- Throughput: Thông lượng (lưu lượng xử lý).
- Error rates: Tỷ lệ lỗi.
SRE, Cloud và Cloud native development
Khi các tổ chức chuyển từ hạ tầng CNTT truyền thống và các trung tâm dữ liệu tại chỗ (on-premises) sang mô hình hybrid cloud (đám mây lai), họ thường tạo ra khối lượng dữ liệu vận hành lớn hơn. SRE đóng vai trò quan trọng trong việc sử dụng lượng dữ liệu này để tự động hóa quản trị hệ thống, vận hành và ứng phó sự cố, đồng thời nâng cao độ tin cậy của doanh nghiệp khi môi trường CNTT ngày càng trở nên phức tạp.
Cách tiếp cận phát triển cloud native (cloud-native development), cụ thể là xây dựng ứng dụng dưới dạng microservices và triển khai chúng trong container, có thể giúp đơn giản hóa quá trình phát triển, triển khai và mở rộng ứng dụng. Tuy nhiên, cloud-native development cũng tạo ra một môi trường ngày càng phân tán, khiến việc quản trị, vận hành CNTT và quản lý trở nên phức tạp hơn.
Một đội ngũ SRE có thể hỗ trợ tốc độ đổi mới nhanh mà cách tiếp cận cloud-native mang lại, đồng thời cải thiện độ tin cậy của hệ thống mà không làm gia tăng thêm áp lực vận hành lên các nhóm DevOps.

Kết lại, Site Reliability Engineering không chỉ là một vai trò kỹ thuật mà còn là cách tiếp cận giúp doanh nghiệp xây dựng hệ thống ổn định, linh hoạt và sẵn sàng mở rộng trong dài hạn. Khi áp dụng đúng SRE, doanh nghiệp có thể cân bằng tốt giữa tốc độ phát triển tính năng và độ tin cậy của dịch vụ, đồng thời giảm thiểu rủi ro vận hành. Trong bối cảnh hạ tầng ngày càng phức tạp, việc hiểu rõ Site Reliability Engineering là gì sẽ là nền tảng quan trọng để nâng cao hiệu quả vận hành và chất lượng trải nghiệm người dùng.